- Introduction

https://www.cloudskillsboost.google/paths/11
https://storage.googleapis.com/cloud-training/gcpace/2.0/en/student/ACE_Workbook_v2.0.pdf
O que é um Associate Cloud Engineer?
Um Associate Cloud Engineer implanta e protege aplicativos e a infraestrutura, monitora operações de vários projetos e mantém soluções empresariais para garantir que elas atendam às métricas de desempenho desejadas
Esse profissional tem experiência em trabalhar com nuvens públicas e soluções locais..
Ele sabe usar o console do Google Cloud e a interface da linha de comando para realizar tarefas comuns na plataforma e manter e dimensionar uma ou mais soluções implantadas que usam os serviços gerenciados pelo Google ou autogerenciados no Google Cloud.
- Setting Up a Cloud Solution Environment

Agora vamos revisar como usar essas perguntas de diagnóstico para ajudá-lo a identificar o que incluir em seu plano de estudos.
Como lembrete: este não é um curso intensivo que ensina tudo o que você precisa saber sobre como configurar uma solução no Google Cloud. Em vez disso, o objetivo é dar a você uma noção melhor do escopo da seção e das diferentes habilidades que você deseja desenvolver ao se preparar para a certificação
Abordaremos esta revisão examinando os objetivos desta seção do exame e as perguntas que você acabou de responder sobre cada um deles. Apresentaremos um objetivo, revisaremos brevemente as respostas às perguntas relacionadas e, em seguida, falaremos sobre onde você pode encontrar mais informações nos recursos de aprendizagem e/ou na documentação do Google Cloud. À medida que avançamos em cada objetivo da seção, use a página da sua apostila para marcar a documentação, os cursos (e os módulos!) específicos e os emblemas de habilidades que você deseja enfatizar no seu plano de estudos.
- Question 1 tested your ability to assign users to IAM roles.
- Question 2 explored using organization resource hierarchies in Google Cloud, and question 3 tested your knowledge of the relationship between resources and projects to track resource usage, billing, or permissions.
- Question 4 examined concepts of permission hierarchy, and questions 5 and 6 tested your knowledge of roles in Google Cloud.
1. Question: Stella is a new member of a team in your company who has been put in charge of monitoring VM instances in the organization. Stella will need the required permissions to perform this role. How should you grant her those permissions?
A. Assign Stella a roles/compute.viewer role.
B. Assign Stella compute.instances.get permissions on all of the projects she needs to monitor.
C. Add Stella to a Google Group in your organization. Bind that group to roles/compute.viewer.
D. Assign the “viewer” policy to Stella.
Feedback:
A. Incorrect. You should not assign roles to an individual user. Users should be added to groups and groups assigned roles to simplify permissions management.
B. Incorrect. Roles are combinations of individual permissions. You should assign roles, not individual permissions, to users.
* C. Correct! Best practice is to manage role assignment by groups, not by individual users.
D. Incorrect. A policy is a binding that is created when you associate a user with a role. Policies are not "assigned" to a user.
Where to look: https://cloud.google.com/iam/docs/overview
Summary: You assign members to roles through an IAM (Identity and Access Management) policy. Roles are combinations of permissions needed for a role. Members can be a Google account, a service account, a Google group, a Google Workspace domain, a Cloud Identity domain, all authenticated users, and all users. A service account is an account for an application instead of an end user. IAM lets administrators authorize who can take action on specific resources. An IAM policy has a “who” part, a “can do what” part, and an “on which resource” part.
2. Question: How are resource hierarchies organized in Google Cloud?
A. Organization, Project, Resource, Folder.
B. Organization, Folder, Project, Resource.
C. Project, Organization, Folder, Resource.
D. Resource, Folder, Organization, Project.
Feedback:
A: Incorrect. Folders are optional and come in between organizations and projects.
*B: Correct! Organization sits at the top of the Google Cloud resource hierarchy. This can be divided into folders, which are optional. Next, there are projects you define. Finally, resources are created under projects.
C: Incorrect. Organization is the highest level of the hierarchy.
D: Incorrect. Organization is the highest level of the hierarchy, followed by optional folders, projects, and then resources.
Where to look: https://cloud.google.com/resource-manager/docs/cloud-platform-resource-hierarchy#r esource-hierarchy-detail
Summary: You may find it easiest to understand the Google Cloud resource hierarchy from the bottom up. All the resources you use--whether they’re virtual machines, Cloud Storage buckets, tables in BigQuery, or anything else in Google Cloud--are organized into projects. Optionally, these projects may be organized into folders; folders can contain other folders. All the folders and projects used by your organization can be brought together under an organization node. Projects, folders, and organization nodes are all places where policies can be defined. Some Google Cloud resources let you put policies on individual resources too, like Cloud Storage buckets. Policies are inherited downwards in the hierarchy.

Question 3: What Google Cloud project attributes can be changed?
A. The Project ID.
B. The Project Name.
C. The Project Number.
D. The Project Category
Feedback:
A: Incorrect. Project ID is set by the user at creation time but cannot be changed. It must be unique.
*B: Correct! Project name is set by the user at creation. It does not have to be unique. It can be changed after creation time.
C: Incorrect. Project number is an automatically generated unique identifier for a project. It cannot be changed.
D: Incorrect. Project category isn't a valid attribute when setting up a Google Cloud project.
Where to look: https://cloud.google.com/resource-manager/docs/cloud-platform-resource-hierarchy# projects
Summary: A project is required to use Google Cloud, and forms the basis for creating, enabling, and using all Google Cloud services, managing APIs, enabling billing, adding and removing collaborators, and managing permissions. In order to interact with most Google Cloud resources, you must provide the identifying project information for every request. You can identify a project in either of two ways: a project ID, or a project number. A project ID is the customized name you chose when you created the project. If you activate an API that requires a project, you will be directed to create a project or select a project using its project ID. (Note that the name string, which is displayed in the UI, is not the same as the project ID.) A project number is automatically generated by Google Cloud. Both the project ID and project number can be found on the dashboard of the project in the Google Cloud console. For information on getting project identifiers and other management tasks for projects see Creating and Managing Projects. The initial IAM policy for the newly created project resource grants the owner role to the creator of the project.
4. Question: Jane will manage objects in Cloud Storage for the Cymbal Superstore. She needs to have access to the proper permissions for every project across the organization. What should you do?
A. Assign Jane the roles/storage.objectCreator
on every project.
B. Assign Jane the roles/viewer on each
project and the roles/storage.objectCreator
for each bucket.
C. Assign Jane the roles/editor at the
organizational level.
D. Add Jane to a group that has the
roles/storage.objectAdmin role assigned at
the organizational level.
Feedback:
A. Incorrect. Inheritance would be a better way to handle this scenario. The roles/storage.objectCreator role does not give the permission to delete objects, an essential part of managing them.
B. Incorrect. This role assignment is at too low of a level to allow Jane to manage objects.
C. Incorrect. Roles/editor is basic and would give Jane too many permissions at the project level.
*D. Correct! This would give Jane the right level of access across all projects in your company.
Where to look: https://cloud.google.com/resource-manager/docs/cloud-platform-resource-hierarchy
Summary: Resource hierarchy is different from Identity and Access Management. Identity and Access Management focuses on who, and lets the administrator authorize who can take action on specific resources based on permissions. Organization Policy focuses on what, and lets the administrator set restrictions on specific resources to determine how they can be configured. A constraint is a particular type of restriction against a Google Cloud service or a list of Google Cloud services. A constraint has a type, either list or boolean.

5.Question: You need to add new groups of employees in Cymbal Superstore’s production environment. You need to consider Google’s recommendation of using least privilege. What should you do?
A. Grant the most restrictive basic role to most services,
grant predefined or custom roles as necessary.
B. Grant predefined and custom roles that provide
necessary permissions and grant basic roles only
where needed.
C. Grant the least restrictive basic roles to most services
and grant predefined and custom roles only when
necessary.
D. Grant custom roles to individual users and implement
basic roles at the resource level.
Feedback:
A: Incorrect. Basic roles are too broad and don’t provide least privilege.
*B: Correct! Basic roles are broad and don’t use the concept of least privilege. You should grant only the roles that someone needs through predefined and custom roles.
C: Incorrect. Basic roles apply to the project level and do not provide least privilege.
D: Incorrect. You should see if a predefined role meets your needs before implementing a custom role.
Where to look: https://cloud.google.com/iam/docs/understanding-roles#role_types
Summary:

There are three types of roles in IAM:
● Basic roles, which include the Owner, Editor, and Viewer roles that existed
prior to the introduction of IAM.
● Predefined roles, which provide granular access for a specific service and are
managed by Google Cloud.
● Custom roles, which provide granular access according to a user-specified list
of permissions.
Basic roles are the Owner, Editor, and Viewer.
Pre-defined roles bundle selected permissions up into collections that correlate with
common job-related business needs.
6.Question: The Operations Department at Cymbal Superstore wants to provide managers access to information about VM usage without allowing them to make changes that would affect the state. You assign them the Compute Engine Viewer role. Which two permissions will they receive?
A. compute.images.list
B. compute.images.get
C. compute.images.create
D. compute.images.setIAM
E. computer.images.update
Feedback:
*A: Correct! Viewer can perform read-only actions that do not affect state.
*B: Correct! Get is read-only. Viewer has this permission.
C: Incorrect. This permission would change state.
D: Incorrect. Only the Owner can set the IAM policy on a service.
E: Incorrect. Only Editor and above can change the state of an image.
Where to look: https://cloud.google.com/iam/docs/understanding-roles#basic
Summary: If you’re a viewer on a given resource, you can examine it but not change its state. If you’re an editor, you can do everything a viewer can do plus change its state. And if you’re an owner, you can do everything an editor can do plus manage roles and permissions on the resource.
Now that we’ve reviewed the diagnostic questions related to Section 1.1 Setting up cloud projects and account, let’s take a moment to consider resources that can help you build your knowledge and skills in this area.
The concepts in the diagnostic questions we just reviewed are covered in these modules, skill badges, and documentation. You’ll find this list in your workbook so you can take a note of what you want to include later when you build your study plan. Based on your experience with the diagnostic questions, you may want to include some or all of these.
Google Cloud Fundamentals: Core Infrastructure (On-demand)
Architecting with Google Compute Engine (ILT)
Essential Google Cloud Infrastructure: Core Services (On-demand)
Implement Load Balancing on Compute Engine (Skill Badge)
Set Up an App Dev Environment on Google Cloud (Skill Badge)
https://cloud.google.com/iam/docs/overview
https://cloud.google.com/resource-manager/docs/cloud-platform-resource-hierarchy
https://cloud.google.com/iam/docs/understanding-roles
Agora vamos nos concentrar na Seção 1.2. Um Associate Cloud Engineer precisa ser capaz de gerenciar a configuração de cobrança de uma solução em nuvem, o que envolve tarefas como configuração de contas de cobrança, vinculação de projetos, estabelecimento de alertas de orçamento e configuração de exportações. A pergunta 7 testou seu conhecimento sobre contas de cobrança e a função de administrador de cobrança. A pergunta 8 explorou alertas orçamentários.
7.Question: How are billing accounts applied to projects in Google Cloud? (Pick two.)
A. Set up Cloud Billing to pay for usage costs in
Google Cloud projects and Google
Workspace accounts.
B. A project and its resources can be tied to
more than one billing account.
C. A billing account can be linked to one or
more projects.
D. A project and its resources can only be tied
to one billing account.
E. If your project only uses free resources you
don’t need a link to an active billing account.
Feedback:
A: Incorrect. Cloud Billing does not pay for charges associated with a Google Workspace account.
B: Incorrect. A project can only be linked to one billing account at a time.
*C: Correct! A billing account can handle billing for more than one project.
*D: Correct! A project can only be linked to one billing account at a time.
E: Incorrect. Even projects using free resources need to be tied to a valid Cloud Billing account.
Where to look: https://cloud.google.com/billing/docs/how-to/manage-billing-accoun
Summary: Cloud Billing accounts pay for usage costs in Google Cloud projects and Google Maps Platform projects. Cloud Billing accounts do not pay for Google Workspace accounts. Google Workspace customers need a separate Google Workspace billing account. A project and its service-level resources are linked to one Cloud Billing account at a time. A Cloud Billing account operates in a single currency and is linked to a Google payments profile. A Cloud Billing account can be linked to one or more projects. Usage costs are tracked by Project and are charged to the linked Cloud Billing account. Important: Projects that are not linked to an active Cloud Billing account cannot use Google Cloud or Google Maps Platform services. This is true even if you only use services that are free. If you want to change the Cloud Billing account that you are using to pay for a project (that is, link a project to a different Cloud Billing account), see Enable, disable, or change billing for a project. You can manage your Cloud Billing accounts using the Google Cloud console. For more information about the console, visit General guide to the console.
8.Fiona is the billing administrator for the project associated with Cymbal Superstore’s eCommerce application. Jeffrey, the marketing department lead, wants to receive emails related to budget alerts. Jeffrey should have access to no additional billing information.
A. Change the budget alert default threshold
rules to include Jeffrey as a recipient.
B. Use Cloud Monitoring notification channels
to send Jeffrey an email alert.
C. Add Jeffrey and Fiona to the budget scope
custom email delivery dialog.
D. Send alerts to a Pub/Sub topic that Jeffrey is
subscribed to.
Feedback:
A. Incorrect. To add Jeffrey as a recipient to the default alert behavior you would have to grant him the role of a billing administrator or billing user. The qualifier in the questions states he should have no additional access.
*B. Correct! You can set up to 5 Cloud Monitoring channels to define email recipients that will receive budget alerts.
C. Incorrect. Budget scope defines what is reported in the alert.
D. Incorrect. Pub/Sub is for programmatic use of alert content.
Where to look: https://cloud.google.com/billing/docs/how-to/budgets
Summary: To create a new budget, complete the following steps:
1. Create and name the budget
2. Set the budget scope
3. Set the budget amount
4. Set the budget threshold rules and actions
5. Click finish to save the new budget
Threshold rules define the triggering events used to generate a budget notification email. Note that threshold rules are required for email notifications and are used specifically to trigger email notifications. Thresholds rules are not required for programmatic notifications, unless you want your programmatic notifications to include data about the thresholds you set.
Email notification settings can be either role-based, which sends alerts to the Billing account Administrator and Billing Account Users. This is the default behavior. Or you can set up Cloud Monitoring notification channels to send alerts to email addresses of your choice.
Let’s take a moment to consider resources that can help you build your knowledge and skills in this area. The concepts in the diagnostic questions we just reviewed are covered in these modules and in this documentation. You’ll find this list in your workbook so you can take a note of what you want to include later when you build your study plan. Based on your experience with the diagnostic questions, you may want to include some or all of these.
Google Cloud Fundamentals: Core Infrastructure (On-demand)
Architecting with Google Compute Engine (ILT)
Essential Google Cloud Infrastructure: Core Services (On-demand)
https://cloud.google.com/billing/docs/how-to/manage-billing-account https://cloud.google.com/billing/docs/how-to/budgets
Há quatro maneiras de interagir com o Google Cloud: o console do Google Cloud, o Cloud SDK e o Cloud Shell, o Cloud Mobile App e as APIs. Como Associate Cloud Engineer, você deverá estar familiarizado com todas elas.
A pergunta 9 testou seu conhecimento sobre maneiras de interagir com os serviços do Google Cloud, e a pergunta 10 pediu que você diferenciasse os principais componentes do SDK do Google Cloud (gcloud, gcloud storage e bq).
9.Question: Pick two choices that provide a command line interface to Google Cloud.
A. Google Cloud console
B. Cloud Shell
C. Cloud Mobile App
D. Cloud SDK
E. REST-based API
Feedback:
A: Incorrect. The console is a graphical interface.
*B: Correct! Cloud Shell provides a cloud-based CLI environment.
C: Incorrect. The Cloud Mobile App allows you to interact graphically with your Google Cloud resources through an app on your mobile device.
*D: Correct! The Cloud SDK provides a local CLI environment.
E: Incorrect. This interface allows API access through CURL or client-based programming SDKs.
Where to look: https://cloud.google.com/docs/overview#ways_to_interact_with_the_services
Summary: The Google Cloud console provides a web-based, graphical user interface that you can use to manage your Google Cloud projects and resources. The gcloud tool lets you manage development workflow and Google Cloud resources in a terminal window. You can run gcloud commands by installing the Cloud SDK, which includes the gcloud tool. You use it by opening a terminal window on your own computer. You can also access gcloud commands by using Cloud Shell, a browser-based shell that runs in the cloud. Client libraries are also provided by the Cloud SDK. They provide access to API’s for access to services, called application API’s, and Admin API’s which allow you to automate resource management tasks.

The Cloud SDK is a set of tools that you can use to manage resources and applications hosted on Google Cloud. These include the gcloud tool, which provides the main command-line interface for Google Cloud Platform products and services, as well as gcloud storage and bq. When installed, all of the tools within the Cloud SDK are located under the bin directory.
Cloud Shell provides you with command-line access to your cloud resources directly from your browser. Cloud Shell is a Debian-based virtual machine with a persistent 5-GB home directory, which makes it easy for you to manage your Google Cloud projects and resources. With Cloud Shell, the Cloud SDK gcloud command and other utilities you need are always installed, available, up to date, and fully authenticated when you need them.
For more information on the SDK command-line tools, see: https://cloud.google.com/sdk/cloudplatform
Note: Currently, the App Engine SDKs are separate downloads. For more information, see: https://cloud.google.com/appengine/downloads
Cloud Shell provides the following:
● A temporary Compute Engine virtual machine instance running a
Debian-based Linux operating system
● Command-line access to the instance from a web browser using terminal
windows in the Google Cloud console
● 5 GB of persistent disk storage per user, mounted as your $HOME directory in
Cloud Shell sessions across projects and instances
● The Cloud SDK and other tools pre-installed on the Compute Engine instance
● Language support, including SDKs, libraries, runtime environments and
compilers for Java, Go, Python, Node.js, PHP and Ruby
● Web preview functionality, which allows you to preview web applications
running on the Cloud Shell instance through a secure proxy
● Built-in authorization for access to projects and resources
You can use Cloud Shell to:
● Create and manage Compute Engine instances.
● Create and access Cloud SQL databases.
● Manage Cloud Storage data.
● Interact with hosted or remote Git repositories, including Cloud Source
Repositories.
● Build and deploy App Engine applications.
You can also use Cloud Shell to perform other management tasks related to your projects and resources, using either the gcloud command or other available tools.
10.Question: You want to use the Cloud Shell to copy files to your Cloud Storage bucket. Which Cloud SDK command should you use?
A. gcloud
B. gcloud storage
C. bq
D. Cloud Storage Browser
Feedback:
A: Incorrect. gcloud provides tools for interacting with resources and services in the Cloud SDK.
*B: Correct! Use gcloud storage to interact with Cloud Storage via the Cloud SDK.
C: Incorrect. bq is a way to submit queries to BigQuery.
D: Incorrect. Cloud Storage Browser is part of the Google Cloud console, not CLI-based.
Where to look: https://cloud.google.com/sdk/docs/components
Summary: gcloud Default gcloud CLI Commands Tool for interacting with Google Cloud. Only commands at the General Availability and Preview release levels are installed with this component. You must separately install the gcloud alpha Commands and/or gcloud beta Commands components if you want to use commands at other release levels. bq BigQuery Command-Line Tool Tool for working with data in BigQuery gcloud storage Cloud Storage Command-Line Tool Tool for performing tasks related to Google Cloud Storage.
Google Cloud Fundamentals: Core Infrastructure (On-demand)
Architecting with Google Compute Engine (ILT)
Essential Google Cloud Infrastructure: Core Services (On-demand)
Implement Load Balancing on Compute Engine (Skill Badge)
Set Up an App Dev Environment on Google Cloud (Skill Badge)
https://cloud.google.com/docs/overview#ways_to_interact_with_the_services https://cloud.google.com/sdk/docs/components https://cloud.google.com/sdk/gcloud/reference https://cloud.google.com/bigquery/bq-command-line-tool https://cloud.google.com/sdk/gcloud/reference/storage
Knowledge Check
1. Which Google Cloud interface allows for scripting actions in a set of command line executables?
Google Cloud console.
Cloud Mobile App.
(x) Cloud Shell.
REST API.
Cloud Shell provides a containerized command line interface that allows you to run commands and automate them with scripts.
2. What is the lowest level basic role that gives you permissions to change resource state?
Administrator.
Viewer.
Owner.
(x) Editor.
Editor gives you permissions to change state.
- Planning and Configuring a Cloud Solution


https://cloud.google.com/products/calculator/ The Pricing Calculator is a multi-section form that lets you estimate the costs of different cloud services based on how you are going to use and configure them. For example, you can estimate costs of implementing a database in Cloud SQL, object storage in Cloud Storage, data warehouse needs using BigQuery, among others. Once you have some possible configurations in mind, you can use the pricing calculator to estimate costs for the different products you will be using.



B. App Engine
C. Google Kubernetes Engine
D. Compute Engine

This question relates to Google Cloud data services and what data construct they are based on.
- Firestore and Bigtable are NoSQL implementations. Firestore is a document database that supports entities and attributes. Bigtable is based on column families where rows of data are referenced by a key that combines commonly queried columns. Related columns can additionally be organized into column families such as username and address.
- Cloud Storage is Google Cloud’s recommended object storage service. Think of pictures and videos, as well as file objects with an implicit schema, such as logs and csv files.
- Google’s relational database offerings include Cloud SQL and Spanner. Use them when you need a transactional processing system you can query with SQL. Cloud SQL is a managed version of databases you can implement on-premises, while Spanner is horizontally scalable and globally available.
- BigQuery is a serverless distributed query engine that is primarily used as a modern data warehouse. It does have a native storage format but can also query external data where it resides. You interact with it by using a form of SQL. Keep in mind its native storage format is not a good solution for a backend store for an application. It does, however, improve performance of analytical queries you run against it using the query engine.

Data location and storage class affect the availability and cost of storing your data in Cloud Storage. You can choose regional, dual-region, and multi-regional location options. Storage classes include Standard, Nearline, Coldline and Archive storage. The different storage classes determine pricing based on how long your data is stored and how often you access it. Standard storage is the default storage class. Data stored using this class is immediately available. It is the recommended storage class for frequently accessed data. You should locate your data in the same region as the services you are going to use to ingest and analyze the data to reduce latency as much as possible. Specifying a dual-region location that includes the region where your application resides will still give you low latency, but your data will also be available in another region in case of an outage. Extending your storage settings to a multi-region will make data available over a large geographic area such as US, Europe, or Asia. The other storage classes implement ways to store infrequently accessed data. Nearline storage is for data that is only accessed around every 30 days. Coldline storage is for data that is only accessed around once every quarter, or 90 days. Archive storage is long-term storage for data accessed only once a year. These storage classes have optimized pricing, but also expect you to keep your data in them for the minimum limits specified above. If you access your data before the minimum amount of time you will be charged a data access fee.

- transactional workloads
- analytical workloads.
- Transactional workloads are optimized for more writes and updates than reads. Transactional means either all parts of an update happen or none of them do. For example, think of the importance of making sure deposits and withdrawals are recorded in a financial system. Both of these are part of one transaction.
- Relational database management systems are commonly used for applications that are transactional in nature. Relational database services used to support transactional systems in Google Cloud include Cloud SQL and Spanner.
- The other type of workload is analytical. It is based on querying historical data that doesn’t change often, and is optimized for writes. BigQuery is a good option for this kind of workload.
A. Implement a premium tier pass-through external https load balancer connected to the web tier as the frontend and a regional internal load balancer between the web tier and backend.
B. Implement a proxied external TCP/UDP network load balancer connected to the web tier as the frontend and a premium network tier ssl load balancer between the web tier and the backend.
C. Configure a standard tier proxied external https load balancer connected to the web tier as a frontend and a regional internal load balancer between the web tier and the backend.
D. Configure a proxied SSL load balancer connected to the web tier as the frontend and a standard tier internal TCP/UDP load balancer between the web tier and the backend.
Feedback:
A. Implement a premium tier pass-through external https load balancer connected to the web tier as the frontend and a regional internal load balancer between the web tier and backend. Feedback: Incorrect. Premium external https load balancer is global and more expensive. All the resources for the scenario are in the same region. Also, https load balancer is proxied, not pass-through.
B. Implement a proxied external TCP/UDP network load balancer connected to the web tier as the frontend and a premium network tier ssl load balancer between the web tier and the backend. Feedback: Incorrect. TCP/UDP is a pass-through balancer. Premium tier SSL is global and is not the proper solution between web and backend within a region.
*C. Configure a standard tier proxied external https load balancer connected to the web tier as a frontend and a regional internal load balancer between the web tier and the backend. Feedback: Correct! A standard tier proxied external load balancer is effectively a regional resource. A regional internal load balancer doesn’t require external IPs and is more secure.
D. Configure a proxied SSL load balancer connected to the web tier as the frontend and a standard tier internal TCP/UDP load balancer between the web tier and the backend. Feedback: Incorrect. SSL load balancer is not a good solution for web front ends. For a web frontend, you should use an HTTP/S load balancer (layer 7) whenever possible.
Where to look: https://cloud.google.com/load-balancing/docs/load-balancing-overview
Summary:

An important consideration when designing an application accessed by end users is load balancing. Load balancing takes user requests and distributes them across multiple instances of your application. This helps to keep your application from experiencing performance issues if there is a spike in user activity.
- As a review, layer 7 is the the application layer of the protocol stack. It is where applications, or processes, share data with each other. It uses lower levels of the stack to pipe connections to other processes. The hypertext transfer protocol (http) and file transfer protocol (ftp) are examples of Layer 7 protocols.
- Layer 4 of the OSI model encapsulates host-to-host communication in both the Transport and Network levels. Google cloud offers both internal and external load balancers. The external load balancers include https, SSL, and TCP load balancers. Internal load balancers include TCP/UDP, http(s), and network pass-through load balancers. The http(s) load balancers live at Layer 7 of the OSI model.
- TCP/UDP, SSL and network load balancers reside at Layer 4 of the OSI model. In Google Cloud, load balancers can be be proxied or pass-through. Proxied load balancers terminate connections and proxy them to new connections internally. Pass-through load balancers pass the connections directly to the backends.
Diagnostic Question 10 Discussion: What Google Cloud load balancing option runs at Layer 7 of the TCP stack?
A. Global http(s)
B. Global SSL Proxy
C. Global TCP Proxy
D. Regional Network
Feedback:
*A. Global http(s) Feedback: Correct! https(s) is an application protocol, so it lives at layer 7 of the TCP stack.
B. Global SSL Proxy Feedback: Incorrect. SSL is a layer 4 load balancer.
C. Global TCP Proxy Feedback: Incorrect. TCP is a layer 4 load balancer.
D. Regional Network Feedback: Incorrect. Regional network is a layer 4 load balancer.
Where to look: https://cloud.google.com/architecture/data-lifecycle-cloud-platform
Summary:

When load balancing in a particular region, external connectivity to your front ends can happen through an external http(s) load balancer with the proper forwarding rules and the standard networking tier. For connectivity internal to your defined vpc network, you should use the internal https and internal TCP/UDP load balancing options. As an Associate Cloud Engineer, you’ll need to be familiar with when to use each option.
Knowledge Check:
1.Which serverless option is based on developing and executing small snippets of code?
(x) - Cloud Functions (Correct! Cloud Functions allows you to submit and execute small snippets of code that fire based on system events.)
- Cloud Run (Incorrect: Cloud Run allows you to run and execute containerized code in a highly concurrent environment).
- Dataflow
- BigQuery
2.Which storage class is designed for long term storage has a 365 day minimum storage agreement, and a lower storage price as compared to other storage types?
Nearline storage
(x) Archive storage (Correct! Archive storage is designed for this use).
Standard storage
Coldline storage
Deploying and Implementing a Cloud Solution

Tasks include:
● Launching a compute instance using Cloud Console and Cloud SDK (GCloud - for example, assign disks, availability policy, SSH keys)
● Creating an autoscaled managed instance group using an instance template
● Generating/uploading a custom SSH key for instances
● Installing and configuring the Cloud Monitoring and Logging Agent
● Assessing compute quotas and requesting increases
Cymbal Superstore uses Compute Engine for their supply chain application to Google
Cloud because they need control over the operating system used by VMs.
Deploying Compute Engine resources can include a range of tasks such as launching
compute instances through the console or cloud sdk and creating identical managed
groups of instances based on an image template. Access requirements might have
you implement SSH keys for you instances. Knowing how to deploy a monitoring
agent on your instances is important to know so you can track performance and make
changes when needed. Finally, if the number of instances starts bumping up against
your project quotas you might need to request increases.
These are the diagnostic questions you answered that relate to this area:
- Question 1: Describe how to configure VMs using Compute Engine machine types (settings such as memory and CPU, GPU if necessary, disk type, temp space)
- Question 2: Apply concepts of managed instance groups, such as availability, scalability, and automated updates
Diagnostic Question 01 Discussion: Cymbal Superstore’s sales department has a medium-sized MySQL database. This database includes user-defined functions and is used internally by the marketing department at Cymbal Superstore HQ. The sales department asks you to migrate the database to Google Cloud in the most timely and economical way. What should you do?
A. Find a MySQL machine image in Cloud
Marketplace and configure it to meet your needs.
B. Implement a database instance using Cloud SQL,
back up your local data, and restore it to the
new instance.
C. Configure a Compute Engine VM with an N2
machine type, install MySQL, and restore your
data to the new instance.
D. Use gcloud to implement a Compute Engine
instance with an E2-standard-8 machine type,
install, and configure MySQL
Feedback:
A. Find a MySQL machine image in Cloud Marketplace and configure it to meet your needs. Feedback: Incorrect. This meets the requirements but is not the most timely way to implement a solution because it requires additional manual configuration.
B. Implement a database instance using Cloud SQL, back up your local data, and restore it to the new instance. Feedback: Incorrect. Cloud SQL does not support user-defined functions, which are used in the database being migrated.
*C. Configure a Compute Engine VM with an N2 machine type, install MySQL, and restore your data to the new instance. Feedback: Correct! N2 is a balanced machine type, which is recommended for medium-large databases.
D. Use gcloud to implement a Compute Engine instance with an E2-standard-8 machine type, install, and configure MySQL. Feedback: Incorrect. E2 is a cost-optimized machine type. A recommended machine type for a medium-sized database is a balanced machine type.
Where to look: https://cloud.google.com/compute/docs/
Summary:

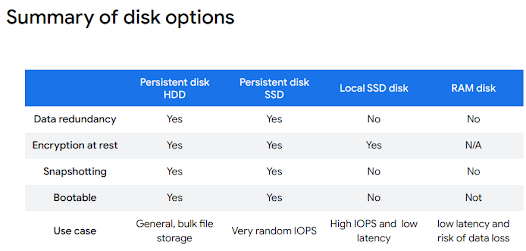
- zonal persistent disks,
- regional persistent disks,
- and local SSD.
Persistent disks are built on network storage devices that are separate from the physical hardware your instance is running on. Each persistent disk references data distributed across several physical disks. Regional persistent disks share replicas of the physical disks across two zones, so you are protected from a single zone outage.
Disk types you can attach to your virtual machine include standard (HDD), SSD, or local SSD. When you create a virtual machine instance in the console it uses balanced SSD, while when you create one via a gcloud command, it uses standard HDD. Balanced SSD gives you higher I/O than standard HDD, but less cost and I/O than fully capable SSD disks.
Local SSDs can be added to your instances based on machine type. They provide very high I/O since they are physically connected to the server your VM is running on. They are ephemeral, and thus go away when your VM is stopped or terminated. Data on your local SSD will survive a reboot. You are responsible for formatting and striping the local SSD per your requirements.
Diagnostic Question 02 Discussion: The backend of Cymbal Superstore’s e-commerce system consists of managed instance groups. You need to update the operating system of the instances in an automated way using minimal resources. What should you do?
A. Create a new instance template. Click Update VMs. Set the update type to Opportunistic. Click Start.
B. Create a new instance template, then click Update
VMs. Set the update type to PROACTIVE.
Click Start.
C. Create a new instance template. Click Update VMs. Set max surge to 5. Click Start.
D. Abandon each of the instances in the managed
instance group. Delete the instance template,
replace it with a new one, and recreate the instances
in the managed group.
Feedback:
A. Create a new instance template. Click Update VMs. Set the update type to Opportunistic. Click Start. Feedback: Incorrect. Opportunistic updates are not interactive.
*B. Create a new instance template, then click Update VMs. Set the update type to PROACTIVE. Click Start. Feedback: Correct! This institutes a rolling update where the surge is set to 1 automatically, which minimizes resources as requested.
C. Create a new instance template. Click Update VMs. Set max surge to 5. Click Start. Feedback: Incorrect. Max surge creates 5 new machines at a time. It does not use minimal resources.
D. Abandon each of the instances in the managed instance group. Delete the instance template, replace it with a new one, and recreate the instances in the managed group. Feedback: Incorrect. This is not an automated approach. The abandoned instances are not deleted or replaced. It does not minimize resource use.
Where to look: https://cloud.google.com/compute/docs/instance-groups/creating-groups-of-managed- instances

Concepts:
● Availability - a managed instance group ensures availability by keeping VM instances running. If a VM fails or stops, the MIG recreates it based on the instance template. You can make your MIG health checks application-based, which looks for an expected response from your application. The MIG will automatically recreate VMs that are not responding correctly. Another availability feature is spreading load across multiple zones using a regional MIG. Finally, you can use a load balancer to evenly distribute traffic across all instances in the group.
● Scalability - you can define autoscaling policies to grow instances in the group to meet demand. They can also scale back down when load drops which reduces cost.
● Automated updates - when it comes time to update software, automated updates lets you define how you will upgrade the instances in a group. You can specify how many resources to use and how many instances can be unavailable at the same time. Available update scenarios include rolling updates and canary updates. Rolling updates define how you want all instances eventually upgraded to the new template. Canary updates let you specify a certain number of instances to upgrade for testing purposes.
Deploying and Implementing Google Kubernetes Engine resources
Tasks include:
● Installing and configuring the command line interface (CLI) for Kubernetes (kubectl)
● Deploying a Google Kubernetes Engine cluster with different configurations including AutoPilot,
regional clusters, private clusters, etc.
● Deploying a containerized application to Google Kubernetes Engine
● Configuring Google Kubernetes Engine monitoring and logging
Cymbal Superstore opted to migrate their on-premises, container-based e-commerce application to GKE. As an Associate Cloud Engineer, you should be comfortable with the Kubernetes CLI, kubectl, and the steps to deploy clusters and applications to GKE. You’ll also need to configure monitoring and logging in GKE. This diagnostic question addressed GKE deployments: Question 3 Create a container development and management environment using Google Kubernetes Engine.
Diagnostic Question 03 Discussion: The development team for the supply chain project is ready to start building their new cloud app using a small Kubernetes cluster for the pilot. The cluster should only be available to team members and does not need to be highly available. The developers also need the ability to change the cluster architecture as they deploy new capabilities. How would you implement this?
A. Implement an autopilot cluster in us-central1-a
with a default pool and an Ubuntu image.
B. Implement a private standard zonal cluster in
us-central1-a with a default pool and an
Ubuntu image.
C. Implement a private standard regional cluster
in us-central1 with a default pool and
container-optimized image type.
D. Implement an autopilot cluster in us-central1
with an Ubuntu image type.
Feedback:
A. Implement an autopilot cluster in us-central1-a with a default pool and an Ubuntu image. Feedback: Incorrect. Autopilot clusters are regional and us-central1-a specifies a zone. Also, autopilot clusters are managed at the pod level.
*B. Implement a private standard zonal cluster in us-central1-a with a default pool and an Ubuntu image. Feedback: Correct! Standard clusters can be zonal. The default pool provides nodes used by the cluster.
C. Implement a private standard regional cluster in us-central1 with a default pool and container-optimized image type. Feedback: Incorrect. The container-optimized image that supports autopilot type does not support custom packages.
D. Implement an autopilot cluster in us-central1 with an Ubuntu image type. Feedback: Incorrect. Autopilot doesn’t support Ubuntu image types.
Where to look: https://cloud.google.com/kubernetes-engine/docs/concepts/types-of-clusters
Summary:

● Availability - in a GKE cluster, availability deals with both the control plane and the distribution of your nodes. A zonal cluster has a single control plane in a single zone. You can distribute the nodes of a zonal cluster across multiple zones, providing node availability in case of a node outage. A regional cluster, on the other hand, has multiple replicas of the control plane in multiple zones with a given region. Nodes in a regional cluster are replicated across three zones, though you can change this behavior as you add new node pools.
Version: At setup you can choose to load a specific version of GKE or enroll in a release channel. If you don’t specify either one of those, the current default version is chosen. It is a best practice to enable auto-upgrade for cluster nodes and the cluster itself.
Network routing: Routing between pods in GKE can be accomplished using alias IPs or Google Cloud Routes. The first option is also known as a VPC-native cluster, and the second one is called a routes-based cluster.
Network Isolation: Public GKE networks let you set up routing from public networks to your cluster. Private networks use internal addresses for pods and nodes and are isolated from public networks. Features: Cluster features for Kubernetes will be either Alpha, Beta, or Stable, depending on their development status.
Let’s take a moment to consider resources that can help you build your knowledge and skills in this area. The concepts in the diagnostic questions we just reviewed are covered in these modules and documentation. You’ll find this list in your workbook so you can take a note of what you want to include later when you build your study plan. Based on your experience with the diagnostic questions, you may want to include some or all of these.
Google Cloud Fundamentals: Core Infrastructure (On-demand)
Getting Started with Google Kubernetes Engine (On-demand)
Develop your Google Cloud Network (Skill Badge)
https://cloud.google.com/kubernetes-engine/docs/concepts/types-of-clusters
Deploying and implementing Cloud Run and Cloud Functions resources
Tasks include, where applicable:
● Deploying an application and updating scaling configuration, versions, and traffic splitting
● Deploying an application that receives Google Cloud events (for example, Pub/Sub events, Cloud
Storage object change notification events)
Cymbal Superstore’s transportation management application uses Cloud Functions.
An Associate Cloud Engineer should be able to deploy and implement serverless
solutions, such as this one which receives Google Cloud events.
These types of tasks were covered in the following questions:
- Question 4.) Differentiate among serverless options including App Engine standard and flexible environment, and Cloud Run.
- Question5.) Describe event function as a service capabilities of Cloud Functions
Diagnostic Question 04 Discussion: You need to quickly deploy a containerized web application on Google Cloud. You know the services you want to be exposed. You do not want to manage infrastructure. You only want to pay when requests are being handled and need support for custom packages. What technology meets these needs?
A. App Engine flexible environment
B. App Engine standard environment
C. Cloud Run
D. Cloud Functions
Feedback:
A. App Engine flexible environment Feedback: Incorrect. App Engine flexible environment does not scale to zero.
B. App Engine standard environment Feedback: Incorrect. App Engine standard environment does not allow custom packages.
*C. Cloud Run Feedback: Correct! Cloud Run is serverless, exposes your services as an endpoint, and abstracts all infrastructure.
D. Cloud Functions Feedback: Incorrect. You do not deploy your logic using containers when developing for Cloud Functions. Cloud Functions executes small snippets of code in a serverless way.
Where to look:
https://cloud.google.com/appengine/docs/the-appengine-environments
https://cloud.google.com/hosting-options
https://cloud.google.com/blog/topics/developers-practitioners/cloud-run-story-serverle
ss-containers
Cloud Run capabilities:
● Serverless Container management
● Based on a service resource
● A service exposes an endpoint
○ Regional
○ Replicated across zones
● Scales based on incoming requests
● Cloud Run provides a service to manage containers in a serverless way, which
means you don’t need to manage infrastructure when you deploy an
application. The main resource container for Cloud Run is a service. A service
is a regional resource that is replicated in multiple zones and exposed as an
endpoint. Underlying infrastructure scales automatically based on incoming
requests. If there are no requests coming in it can scale to zero to save you
money.
● Changes to containers or environment settings create new revisions.
Revisions can be rolled out in a way that supports canary testing by splitting
traffic according to your specifications.
● Cloud Run is built using an open source initiative called knative. It is billed to
the nearest 100 MS as you deploy containers to it.
● Cloud Run can use system libraries and tools made available to the container
environment. It has a timeout of 60 minutes for longer running requests. Cloud
Run can send multiple concurrent requests to each container instance,
improving latency, and saving costs for large volumes of incoming traffic.
Another traditional serverless application manager available in Google Cloud is App Engine. App Engine has two management environments: standard and flexible. In the standard environment, apps run in a sandbox using a specific language runtime. Standard environment is good for rapid scaling. It is limited to specific languages. It can scale to 0 when there is no incoming traffic. It starts up in seconds. In the standard environment you are not allowed to make changes to the runtime. In contrast to the standard environment, App Engine flexible runs in Docker containers in Compute Engine VMs. Flexible supports more programming languages. It can use native code and you can access and manage the underlying Compute Engine resource base. App Engine flexible does not scale to 0. Startup is in minutes. Deployment time is in minutes (longer than standard). It does allow you to modify the runtime environment.
Diagnostic Question 05 Discussion: You need to analyze and act on files being added to a Cloud Storage bucket. Your programming team is proficient in Python. The analysis you need to do takes at most 5 minutes. You implement a Cloud Function to accomplish your processing and specify a trigger resource pointing to your bucket. How should you configure the --trigger-event parameter using gcloud?
A. --trigger-event google.storage.object.finalize
B. --trigger-event google.storage.object.create
C. --trigger-event google.storage.object.change
D. --trigger-event google.storage.object.add
Feedback:
*A. --trigger-event google.storage.object.finalize Feedback: Correct! Finalize event trigger when a write to Cloud Storage is complete.
B. --trigger-event google.storage.object.create Feedback: Incorrect. This is not a cloud storage notification event.
C. --trigger-event google.storage.object.change Feedback: Incorrect. This is not a cloud storage notification event.
D. --trigger-event google.storage.object.add Feedback: Incorrect. This is not a cloud storage notification event.
Where to look: https://cloud.google.com/blog/topics/developers-practitioners/learn-cloud-functions-sn ap https://cloud.google.com/functions

● Cloud Functions is Google Cloud’s answer to serverless functions. It is a fully managed service based on events that happen across your cloud environment, including services and infrastructure. The functions you develop run in response to those events. There are no servers to manage or scaling to configure. The service provides the underlying resources required to execute your function.
● A trigger sends an https request to an endpoint the service is listening on. This endpoint then responds by deploying and executing the function and returning the results specified in your code. Pricing is based on the number of events, compute time, and memory required in network ingress/egress. If no requests are coming in, your function doesn’t cost anything.
● Cloud Functions use cases include IoT processing and lightweight ETL.
● Depending on the programming language you choose, the Cloud Functions service provides a base image and runtime that will be updated and patched automatically. This helps keeps execution of your deployed functions secure.
● By design, functions you write for use by the Cloud Functions service are stateless. If you need to share and persist data across function runs, you should consider using Datastore or Cloud Storage. Each Cloud Function instance handles only one concurrent request at a time. If, while handling a request, another one comes in, Cloud Functions will ask for more instances to be created. This is another reason functions need to be stateless, because they can run on different instances. You can implement minimum instance limits to avoid latency associated with cold starts.
Google Cloud Fundamentals: Core Infrastructure (On-demand)
https://cloud.google.com/appengine/docs/the-appengine-environments
https://cloud.google.com/hosting-options
https://cloud.google.com/blog/topics/developers-practitioners/cloud-run-story-serverless-containers
https://cloud.google.com/blog/topics/developers-practitioners/learn-cloud-functions-snap
https://cloud.google.com/functions
Deploying and implementing data solutions
Tasks include:
● Initializing data systems with products (for example, Cloud SQL, Firestore, BigQuery, Spanner,
Pub/Sub, Bigtable, Dataproc, Dataflow, Cloud Storage)
● Loading data (for example, command line upload, API transfer, import/export, load data from Cloud
Storage, streaming data to Pub/Sub)
Cymbal Superstore has several different data requirements based on the storage needs of their different applications. Their e-commerce system is slated to use Spanner. They need to do analytics on historical data using BigQuery. They need to store their IOT truck data in Bigtable. Their supply chain management system needs a Cloud SQL store. As an Associate Cloud Engineer, you’ll need to be able to deploy and implement a wide range of data solutions. Question tested your knowledge of the steps for setting up a Cloud Storage bucket, question 7 the steps for setting up an instance using Cloud SQL, and question 8 the steps to load data to a BigQuery table.
Diagnostic Question 06 Discussion: You require a Cloud Storage bucket serving users in New York City and San Francisco. Users in London will not use this bucket. You do not plan on using ACLs. What CLI command do you use?
A. Run a gcloud storage objects command and
specify --remove-acl-grant.
B. Run a gsutil mb command specifying a
multi-regional location and an option to turn ACL
evaluation off.
C. Run a gcloud storage buckets create command,
but do not specify –-location.
D. Run a gcloud storage buckets create command
specifying –-placement us-east1, europe-west2.
Feedback:
A. Run a gcloud storage objects command and specify --remove-acl-grant. Feedback: Incorrect. This will remove acl access for a user, but not create a bucket.
B. Run a gsutil mb command specifying a multi-regional location and an option to turn ACL evaluation off. Feedback: Incorrect. gsutil is a minimally maintained CLI command and is being phased out.
*C. Run a gcloud storage buckets create command, but do not specify --location. Feedback: Correct! If you do not specify a location, the bucket will be created by default in the US.
D. Run a gcloud storage buckets create command specifying --placement us-east1, europe-west2 Feedback: Incorrect. The --placement flag only supports regions in the same continent.
Where to look: https://cloud.google.com/storage/docs/creating-buckets https://cloud.google.com/storage/docs/introduction

1. Naming your bucket - has to be globally unique, and not contain any sensitive information
2. Choose location type and option:
● Regional is a specific geographical area where a datacenter campus
resides. It minimizes latency and network bandwidth for consumers
grouped in a specific region
● Dual-region is a a specific pair or regions. It provides geo-redundancy
● Multi-region is a disbursed geographic area, such as the US or Europe.
You can use it to serve content to consumers outside of Google and
distributed over large areas.
3. Pick a default storage class for bucket. You can override this per object.
● Standard is for immediate access and has no minimum storage
duration
● Nearline has a 30 day minimum duration and data retrieval charges
● Coldline has a 90 day min duration and data retrieval charges
● Archive has a 365 day min duration and data retrieval charges
4. Click Create or submit the command.
Diagnostic Question 07 Discussion: Cymbal Superstore asks you to implement Cloud SQL as a database backend to their supply chain application. You want to configure automatic failover in case of a zone outage. You decide to use the gcloud sql instances create command set to accomplish this. Which gcloud command line argument is required to configure the stated failover capability as you create the required instances?
A. --availability-type
B. --replica-type
C. --secondary-zone
D. --master-instance-name
Feedback:
*A. --availability-type Feedback: Correct! This option allows you to specify zonal or regional availability, with regional providing automatic failover to a standby node in another region.
B. --replica-type Feedback: Incorrect. If you have --master-instance-name, this option allows you to define the replica type: a default of read, or a legacy MySQL replica type of failover, which has been deprecated.
C. --secondary-zone Feedback: Incorrect. This is an optional argument that is valid only when you have a specified availability type: regional.
D. --master-instance-name Feedback: Incorrect. This option creates a read replica based on the control plane instance. It replicates data but does not automate failover.
Where to look: https://cloud.google.com/sql/docs/mysql/features https://cloud.google.com/sql/docs/mysql/create-instance
Summary:

Cloud SQL is a Google Cloud service that manages a database instance for you. You are responsible for how you structure your data within it. Cloud SQL can handle common database tasks for you, such as automating backups, implementing high availability, handling data encryption, updating infrastructure and software, and providing logging and monitoring services. You can use it to deploy MySQL, PostgreSQL, or SQL Server databases to Google Cloud. It uses persistent disks attached to underlying Compute Engine instances to house your database, and implements a static IP address for you to connect to it. Steps for setting up a Cloud SQL instance:
1. Create Instance.
2. Select database type.
3. Enter name: do not use sensitive or personally identifiable information. Your instance name can be publicly available.
4. Enter password for root user.
5. Select proper version: choose carefully, it cannot be edited.
6. Regional and zonal availability settings. Can’t be modified. Pick a region where most people will access. You can also choose multi-region.
7. Select both primary and secondary zone. Both default to any with secondary being different than the primary.
8. Config settings include machine type, private or public ip, storage type, storage capacity, threshold for automated storage increase, as well as an increase setting to specify a limit on how big your database grows.
Diagnostic Question 08 Discussion: Cymbal Superstore’s marketing department needs to load some slowly changing data into BigQuery. The data arrives hourly in a Cloud Storage bucket. You want to minimize cost and implement this in the fewest steps. What should you do?
A. Implement a bq load command in a command
line script and schedule it with cron.
B. Read the data from your bucket by using the
BigQuery streaming API in a program.
C. Create a Cloud Function to push data to
BigQuery through a Dataflow pipeline.
D. Use the BigQuery data transfer service to
schedule a transfer between your bucket
and BigQuery.
Feedback:
A. Implement a bq load command in a command line script and schedule it with cron. Feedback: Incorrect. This solution doesn’t cost anything but is more complex than setting up a data transfer.
B. Read the data from your bucket by using the BigQuery streaming API in a program. Feedback: Incorrect. The streaming API has pricing associated with it based on how much data you stream in.
C. Create a Cloud Function to push data to BigQuery through a Dataflow pipeline. Feedback: Incorrect. A Dataflow pipeline will incur charges for the resources performing the sink into BigQuery.
*D. Use the BigQuery data transfer service to schedule a transfer between your bucket and BigQuery. Feedback: Correct! BigQuery transfer service is the simplest process to set up transfers between Cloud Storage and BigQuery. It is encompassed by one command. It is also free.
Where to look: https://cloud.google.com/blog/topics/developers-practitioners/bigquery-explained-data -ingestion https://cloud.google.com/bigquery/docs/loading-data

Nenhum comentário:
Postar um comentário