Algumas das primeiras técnicas usadas para analisar texto com computadores envolvem a análise estatística de um corpo de texto (um corpus) para inferir algum tipo de significado semântico. De maneira simples, se você conseguir identificar as palavras mais utilizadas em um determinado documento, geralmente poderá obter uma boa compreensão do seu conteúdo.
Geração de tokens
A primeira etapa na análise de um corpus é dividi-lo em tokens. Para simplificar, você pode pensar em cada palavra distinta no texto de treinamento como um token, embora na realidade, tokens possam ser gerados para palavras parciais ou combinações de palavras e pontuação.
Por exemplo, considere esta frase de um famoso discurso presidencial dos EUA: "we choose to go to the moon" (“Nós escolhemos ir para a lua”). A frase pode ser dividida nos seguintes tokens, com identificadores numéricos:
- we
- choose
- até
- GO
- o
- lua
Observe que "to" (número de token 3) é usado duas vezes no corpus. A frase "we choose to go to the moon" pode ser representada pelos tokens [1,2,3,4,3,5,6].
Observação
Usamos um exemplo simples no qual os tokens são identificados para cada palavra distinta no texto. No entanto, considere os seguintes conceitos que podem se aplicar à geração de tokens, dependendo do tipo específico de problema de NLP que você está tentando resolver:
- Normalização de texto: Antes de gerar tokens, você pode optar por normalizar o texto, removendo a pontuação e convertendo todas as palavras para letras minúsculas. Para as análises que dependem apenas da frequência de palavras, essa abordagem melhora o desempenho geral. No entanto, pode ocorrer alguma perda do significado semântico. Por exemplo, considere a frase "A Sra. Rosa plantou uma rosa.". Você pode querer que sua análise diferencie entre a pessoa Sra. Rosa e a rosa que ela plantou. Você também pode querer considerar "rosa". como um token separado de "rosa", porque a inclusão de um ponto fornece a informação de que a palavra está no final de uma frase
- Remoção de palavra irrelevante (stop word). Palavras vazias são palavras que devem ser excluídas da análise. Por exemplo, o, a ou uns facilitam a leitura do texto para as pessoas, mas acrescentam pouco significado semântico. Ao excluir essas palavras, uma solução de análise de texto pode ser mais capaz de identificar as palavras importantes.
- n-gramas são frases constituídas de vários termos, como "eu tenho" ou "ele andou". Uma frase de uma única palavra é um unigrama, uma frase de duas palavras é um bigrama, uma frase de três palavras é um trigrama e assim por diante. Ao considerar as palavras como grupos, um modelo de machine learning pode entender melhor um texto.
- A lematização é uma técnica na qual algoritmos são aplicados para consolidar palavras antes de contá-las, de forma que palavras com a mesma raiz, como “poder”, “poderoso” e “empoderado”, sejam interpretadas como sendo o mesmo token.
Análise de frequência
Depois de gerar os tokens das palavras, você pode executar algumas análises para contar o número de ocorrências de cada token. As palavras mais usadas (além de palavras de parada como "a", "o" e assim por diante) muitas vezes podem fornecer uma pista sobre o assunto principal de um corpus de texto. Por exemplo, as palavras mais comuns em todo o texto do discurso "go to the moon", que consideramos anteriormente, incluem "new", "go", "space" e "moon". Se decidíssemos gerar tokens do texto como bigramas (pares de palavras), o bigrama mais comum na fala seria "a lua". A partir dessas informações, podemos facilmente presumir que o texto trata principalmente de viagens espaciais e de ir para a lua.
Dica
Uma análise de frequência simples, em que você apenas conta quantas vezes cada token aparece, pode ser eficaz para analisar um único documento. No entanto, quando você precisa distinguir vários documentos dentro do mesmo conjunto, é necessário encontrar uma maneira de identificar quais tokens são mais relevantes em cada um deles. A técnica de Frequência de Termos – Frequência Inversa de Documentos (TF-IDF) é comumente usada para calcular uma pontuação que leva em consideração o número de vezes que uma palavra ou termo aparece em um documento em comparação com sua frequência geral em toda a coleção de documentos. Usando essa técnica, assume-se um alto grau de relevância para palavras que aparecem com frequência em um documento específico, mas relativamente pouco frequente em uma ampla variedade de outros documentos.
Machine learning para classificação de texto
Outra técnica útil de análise de texto é usar um algoritmo de classificação, como regressão logística, para treinar um modelo de machine learning que classifica o texto com base em um conjunto conhecido de categorizações. Uma aplicação comum dessa técnica é treinar um modelo que classifica o texto como positivo ou negativo para executar a análise de sentimento ou a mineração de opiniões.
Por exemplo, considere as seguintes avaliações de um restaurante, que já estão rotuladas como 0 (negativas) ou 1 (positivas):
- A comida e o serviço estavam ótimos: 1
- Uma experiência realmente terrível: 0
- Hmm! comida saborosa e uma vibração boa: 1
- O serviço é lento e a comida medíocre: 0
Com revisões rotuladas suficientes, você pode treinar um modelo de classificação usando o texto tokenizado como características e o sentimento (0 ou 1) como um rótulo. O modelo irá encapsular uma relação entre tokens e sentimento. Por exemplo, revisões com tokens para palavras como "ótimo", "saborosa" ou "boa" são mais propensas a retornar um sentimento de 1 (positivo), enquanto revisões com palavras como "terrível", "lento" e "medíocre" são mais propensas a retornar 0 (negativo).
Modelos de linguagem semântica
À medida que a alta tecnologia em NLP avançou, a capacidade de treinar modelos que encapsulam a relação semântica entre os tokens levou ao surgimento de modelos de linguagem poderosos. No cerne desses modelos está a codificação dos tokens de linguagem como vetores (matrizes de valores múltiplos) conhecidos como inserções.
Pode ser útil pensar nos elementos de um vetor de inserção de token como coordenadas no espaço multidimensional, de modo que cada token ocupe um "local" específico. Quanto mais próximos os tokens estiverem entre si ao longo de uma dimensão específica, mais semanticamente eles estão relacionados. Em outras palavras, as palavras relacionadas ficam agrupadas mais próximas. Como um exemplo simples, suponha que as inserções para nossos tokens consistem em vetores com três elementos, por exemplo:
- 4 ("cachorro"): [10.3.2]
- 5 ("bark"): [10,2,2]
- 8 ("gato"): [10,3,1]
- 9 ("miau"): [10,2,1]
- 10 ("skate"): [3,3,1]
Podemos plotar o local dos tokens com base nesses vetores no espaço tridimensional, desta forma:
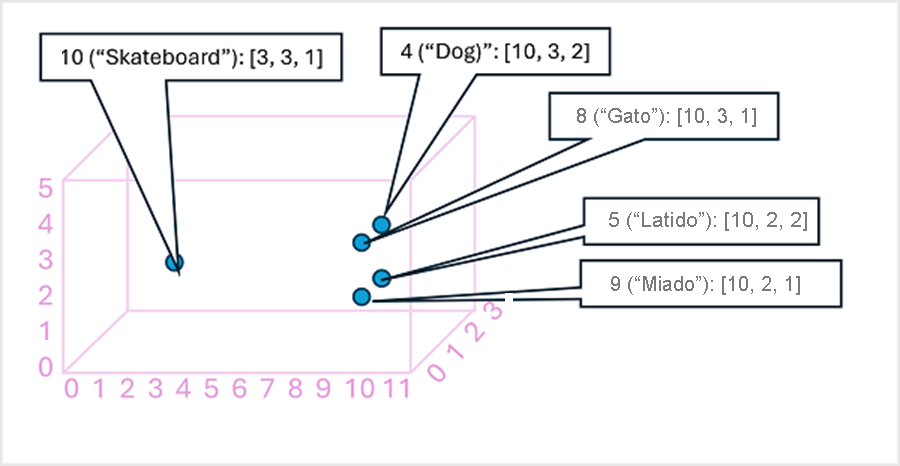
Os locais dos tokens no espaço de inserções incluem algumas informações sobre o quão próximos os tokens estão relacionados uns aos outros. Por exemplo, o token para "cachorro" fica próximo de "gato" e também de "latido". Os tokens para "gato" e "latido" ficam próximos de "miau". O token para "skate" fica mais longe dos outros tokens.
Os modelos de linguagem que usamos no setor são baseados nesses princípios, mas sua complexidade é maior. Por exemplo, os vetores usados geralmente têm um número de dimensões muito maior. Também existem várias maneiras de calcular as incorporações apropriadas para um determinado conjunto de tokens. Métodos diferentes resultam em previsões diferentes dos modelos de processamento de linguagem natural.
O diagrama a seguir mostra uma visão geral das soluções modernas de processamento de linguagem natural. Um grande corpus de texto bruto é tokenizado e usado para treinar modelos de linguagem, que podem suportar muitos tipos diferentes de tarefas de processamento de linguagem natural.
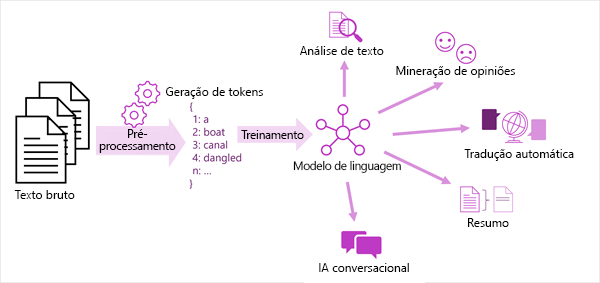
Entre as tarefas comuns de NLP compatíveis com modelos de linguagem incluem-se:
- Análise de texto, como extrair termos chave ou identificar entidades nomeadas no texto.
- Análise de sentimento e mineração de opiniões para categorizar o texto como positivo ou negativo.
- Tradução automática, na qual o texto é convertido automaticamente de um idioma para outro.
- Sumarização, na qual os principais pontos de um grande corpo de texto são resumidos.
- Soluções de IA de conversação, como bots ou assistentes digitais, nas quais o modelo de linguagem pode interpretar a entrada de linguagem natural e retornar uma resposta apropriada.
Estamos acostumados a poder nos comunicar a qualquer momento do dia ou da noite, em qualquer lugar do mundo, colocando as organizações sob pressão para reagir com rapidez em relação às demandas dos clientes. Queremos respostas pessoais para nossas consultas, sem precisar ler a documentação detalhada para encontrar respostas. Isso geralmente significa que a equipe de suporte fica sobrecarregada com solicitações de ajuda por meio de vários canais e que as pessoas são deixadas esperando uma resposta.
A IA de conversação descreve soluções que permitem uma caixa de diálogo entre um agente de IA e um humano. Genericamente, os agentes de IA de conversa são conhecidos como bots. As pessoas podem se envolver com bots por meio de canais como interfaces de chat na Web, email, plataformas de rede social e muito mais.
A resposta a perguntas dá suporte a cargas de trabalho de IA de linguagem natural que exigem um elemento de conversa automatizada. Normalmente, a resposta a perguntas é usada para criar aplicativos de bot que respondem a consultas de clientes. Os recursos de resposta a perguntas podem responder imediatamente, responder a preocupações com precisão e interagir com os usuários de maneira natural com várias transformações. Os bots podem ser implementados em uma variedade de plataformas, como um site ou uma plataforma de rede social.
Os aplicativos de resposta a perguntas fornecem uma maneira amigável de as pessoas obterem respostas para suas dúvidas e permitem que as pessoas lidem com consultas em um momento conveniente para elas, em vez de durante o horário comercial.
No exemplo a seguir, um chat bot usa linguagem natural e fornece opções para um cliente lidar melhor com a consulta. O usuário obtém uma resposta para sua pergunta rapidamente e só é passado para uma pessoa se a consulta for mais complicada.
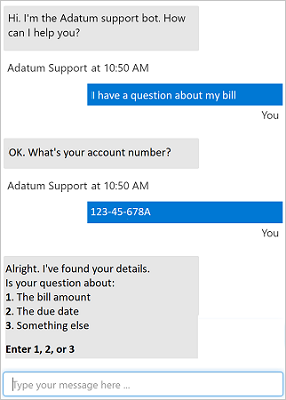
Em 1950, o matemático britânico Alan Turing desenvolveu o Jogo da Imitação, que se tornou conhecido como Teste de Turing, além de levantar a hipótese de que, caso um diálogo seja natural o suficiente, poderá ser impossível saber se você está conversando com um ser humano ou com um computador. Como a IA (inteligência artificial) está se tornando cada vez mais sofisticada, esse tipo de interação conversacional com aplicativos e assistentes digitais será cada vez mais comum. Além disso, em cenários específicos, poderemos ter interações semelhantes à humana com agentes de IA. Os cenários comuns desse tipo de solução incluem aplicativos de atendimento ao cliente, sistemas de reserva, automação residencial, entre outros.
Para perceber a intenção do jogo da imitação, os computadores deverão aceitar o idioma como entrada (no formato de texto ou áudio), além de conseguir interpretar o significado semântico das entradas. Em outras palavras, entender o que está sendo dito.
Para trabalhar com a compreensão da linguagem coloquial, é preciso levar em conta três conceitos principais: enunciados, entidades e intenções.
Declarações
Enunciado é um exemplo de algo que um usuário poderá dizer e que seu aplicativo deverá interpretar. Ao usar um sistema de automação residencial, um usuário poderá usar os seguintes enunciados:
"Ligar o ventilador."
"Ligar as luzes."
Entidades
Uma entidade é um item ao qual um enunciado se refere. Como ventilador e luz nos seguintes enunciados:
"Ligar o ventilador."
"Acender a luz."
É possível considerar as entidades ventilador e luz como instâncias específicas de uma entidade geral do dispositivo.
Intenções
Uma intenção representa a finalidade ou meta expressada no enunciado de um usuário. Por exemplo, para ambos os enunciados considerados anteriormente, a intenção é ligar um dispositivo; portanto, no seu aplicativo de compreensão de linguagem conversacional, você pode definir uma intenção TurnOn relacionada a esses enunciados.
Um aplicativo de compreensão da linguagem coloquial define um modelo que consiste em intenções e entidades. Os enunciados são usados para treinar o modelo com o objetivo de identificar a intenção e as entidades mais prováveis, às quais ele deverá ser aplicado com base em uma determinada entrada.
Depois de definir as entidades e intenções com exemplos de enunciados no seu aplicativo de compreensão de linguagem conversacional, você pode treinar um modelo de linguagem para prever intenções e entidades a partir da entrada do usuário, mesmo que não corresponda exatamente aos exemplos de enunciados. Depois será possível usar o modelo de um aplicativo cliente para recuperar previsões e responder de modo adequado.
Você pode utilizar a compreensão da linguagem coloquial para criar um modelo que preveja intenções e entidades a partir de enunciados de linguagem natural. Um aplicativo cliente poderá usar esse modelo treinado para responder à uma entrada do usuário em uma linguagem natural.
Você pode saber mais sobre a compreensão da linguagem coloquial na documentação do Linguagem de IA do Azure.