A Pesquisa Visual Computacional é uma das principais áreas da IA (inteligência artificial) e se concentra na criação de soluções que permitem que os aplicativos de IA "vejam" o mundo e o compreendam.
É claro que os computadores não têm olhos biológicos que funcionam como os nossos, mas têm funcionalidade para processar imagens, seja de um feed de câmera ao vivo ou de fotografias ou vídeos digitais. Essa capacidade de processar imagens é a chave para criar um software que pode emular a percepção visual humana.
Processamento de imagens e imagem
Antes de explorarmos o processamento de imagens e outras funcionalidades de pesquisa visual computacional, é útil considerar o que uma imagem realmente é no contexto de dados de um programa de computador.
Imagens como matrizes de pixel
Para um computador, uma imagem é uma matriz de valores numéricos de pixel. Por exemplo, considere a seguinte matriz:
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 255 255 255 0 0 0 0 255 255 255 0 0 0 0 255 255 255 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
A matriz consiste em sete linhas e sete colunas, representando os valores de pixel para uma imagem de 7 x 7 pixels (que é conhecida como resolução da imagem). Cada pixel tem um valor entre 0 (preto) e 255 (branco); com valores entre esses limites que representam tons de cinza. A imagem representada por essa matriz é semelhante à seguinte imagem (ampliada):
Aprendizado de máquina para pesquisa visual computacional
A capacidade de usar filtros para aplicar efeitos a imagens é útil em tarefas de processamento de imagem, algo que você pode executar com o software de edição de imagem. No entanto, o objetivo da pesquisa visual computacional é, muitas vezes, extrair significado ou, pelo menos, insights acionáveis de imagens, o que requer a criação de modelos de machine learning treinados para reconhecer recursos com base em grandes volumes de imagens existentes.
Redes neurais convolucionais (CNNs)
Uma das arquiteturas de modelos de machine learning mais comuns para a pesquisa visual computacional é uma rede neural convolucional (CNN). As CNNs usam filtros para extrair mapas de recursos numéricos de imagens e, em seguida, alimentam os valores desses recursos em um modelo de aprendizado profundo para gerar uma previsão de rótulo. Por exemplo, em um cenário de classificação de imagem, o rótulo representa o assunto principal da imagem (em outras palavras, do que se trata essa imagem?). Você pode treinar um modelo de CNN com imagens de diferentes tipos de frutas (como maçã, banana e laranja) para que o rótulo previsto seja o tipo de fruta em uma determinada imagem.
No processo de treinamento de uma CNN, os kernels de filtro são inicialmente definidos usando valores de peso gerados aleatoriamente. À medida que o processo de treinamento avança, as previsões de modelos são avaliadas em relação aos valores dos rótulos conhecidos, e os pesos do filtro são ajustados para melhorar a precisão. Eventualmente, o modelo treinado para classificação de imagens de frutas usa os pesos dos filtros que melhor extraem recursos, ajudando na identificação de diferentes tipos de frutas.
O diagrama a seguir ilustra como funciona uma CNN para um modelo de classificação de imagem: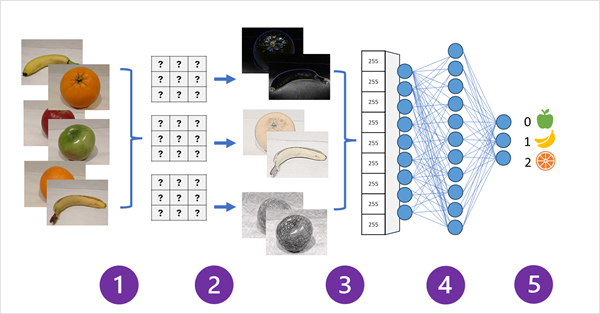
- Imagens com rótulos conhecidos (por exemplo, 0: maçã, 1: banana ou 2: laranja) são alimentadas na rede para treinar o modelo.
- Uma ou mais camadas de filtros são usadas para extrair recursos de cada imagem conforme ela é alimentada pela rede. Os kernels de filtro começam com pesos atribuídos aleatoriamente e geram matrizes de valores numéricos chamados mapas de recursos.
- Os mapas de recursos são mesclados em uma única matriz dimensional de valores de recurso.
- Os valores de recurso são alimentados em uma rede neural totalmente conectada.
- A camada de saída da rede neural usa uma função softmax ou similar para produzir um resultado que contenha um valor de probabilidade para cada possível classe, por exemplo [0,2, 0,5, 0,3].
Durante o treinamento, as probabilidades de saída são comparadas com o rótulo de classe real. Por exemplo, uma imagem de uma banana (classe 1) deve ter o valor [0,0, 1,0, 0,0]. A diferença entre as pontuações de classe previstas e reais é usada para calcular a perda no modelo. Em seguida, os pesos na rede neural totalmente conectada e os kernels de filtro nas camadas de extração de recursos são modificados para reduzir essa perda.
O processo de treinamento é repetido em várias épocas até que um conjunto ideal de pesos seja aprendido. Em seguida, os pesos são salvos e o modelo pode ser usado para prever rótulos de novas imagens para as quais o rótulo é desconhecido.
Observação
Geralmente, as arquiteturas da CNN incluem várias camadas de filtro convolucional e camadas adicionais para reduzir o tamanho dos mapas de recursos, restringir os valores extraídos e manipular os valores dos recursos. Neste exemplo simplificado, essas camadas foram omitidas para se concentrar no conceito principal, que é a utilização dos filtros para extrair recursos numéricos de imagens e, posteriormente, usá-los em uma rede neural para prever rótulos de imagem.
Transformadores e modelos multimodais
As CNNs têm sido o cerne das soluções em pesquisa visual computacional há muitos anos. Embora sejam comumente empregadas para resolver problemas de classificação de imagem, como descrito anteriormente, as CNNs também servem de base para modelos de pesquisa visual computacional mais complexos. Por exemplo, os modelos de detecção de objetos combinam camadas de extração de recursos de CNN com a identificação de regiões de interesse em imagens para localizar várias classes de objeto na mesma imagem.
Conceitos básicos do reconhecimento facial
A análise e detecção facial é uma área da inteligência artificial (IA) que usa algoritmos para localizar e analisar rostos humanos em imagens ou conteúdo de vídeo.
Usos de detecção e análise facial
Há muitos aplicativos para detecção, análise e reconhecimento facial. Por exemplo,
- O reconhecimento do rosto para fins de segurança pode ser usado na criação de aplicativos de segurança e cada vez mais é usado em sistemas operacionais de smartphones para desbloquear esses dispositivos.
- Mídia social – o reconhecimento do rosto pode ser usado para marcar automaticamente os amigos conhecidos em fotos.
- Monitoramento inteligente – por exemplo, um automóvel pode incluir um sistema que monitora o rosto do motorista para determinar se ele está olhando para a estrada, olhando para um dispositivo móvel ou mostrando sinais de cansaço.
- Publicidade – a análise de rostos em uma imagem pode ajudar a direcionar anúncios para um público-alvo demográfico apropriado.
- Pessoas desaparecidas – usando sistemas de câmeras públicas, o reconhecimento do rosto pode ser usado para identificar se uma pessoa desaparecida está no quadro da imagem.
- Validação de identidade – útil em portas de quiosques de entrada em que uma pessoa tem uma permissão de entrada especial.
Entenda a Análise de Detecção Facial
A Detecção Facial envolve a identificação de regiões de uma imagem que contenham um rosto humano, geralmente retornando coordenadas da caixa delimitadora que formam um retângulo ao redor do rosto, como a seguir:
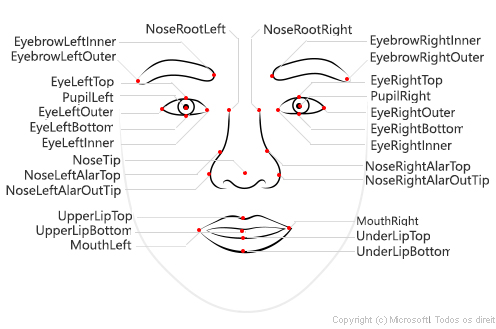
Com a Análise da Detecção Facial, os recursos faciais podem ser utilizados para treinar modelos de machine learning para retornar outras informações, como características faciais como nariz, olhos, sobrancelhas, lábios e outros.
Reconhecimento de rosto
Uma outra aplicação de análise facial é treinar um modelo de machine learning para identificar indivíduos conhecidos com base nos traços do rosto deles. Isso é conhecido como Reconhecimento da Detecção Facial e usa várias imagens de um indivíduo para treinar o modelo. Isso treina o modelo para que ele possa detectar esses indivíduos em novas imagens nas quais não foi treinado.
Como o serviço de Detecção Facial indica o local dos rostos nas imagens?
Um conjunto de coordenadas para cada rosto, definindo uma caixa delimitadora retangular em volta do rosto
Um aspecto que pode prejudicar a detecção facial são os "Ângulos extremos": Os melhores resultados são obtidos quando os rostos estão em posição totalmente frontal ou o mais próximo possível dessa posição
Suponha que você tenha arquivos de imagem de placas de trânsito, anúncios ou palavras escritas a giz em um quadro negro. Os computadores podem ler o texto nas imagens usando o reconhecimento óptico de caracteres (OCR), a funcionalidade da inteligência artificial (IA) para processar palavras em imagens transformando-as em texto legível por máquina.
Usos do OCR
Automatizar o processamento de texto pode aumentar a velocidade e a eficiência do trabalho ao remover a necessidade de uma inserção de dados manual. A capacidade de reconhecer texto impresso e manuscrito em imagens é benéfica em situações como tomada de notas, digitalização de prontuários médicos ou documentos históricos, verificação de cheques para depósitos bancários e muito mais.
A capacidade dos sistemas de computação de processar textos escritos e impressos é uma área da IA em que a pesquisa visual computacional se cruza com o processamento de linguagem natural. As funcionalidades do Visão são necessárias para "leitura" do texto e, em seguida, as funcionalidades de processamento de linguagem natural dão sentido a ele.
O OCR é a base do processamento de textos em imagens e usa modelos de machine learning treinados para reconhecer formas individuais como letras, numerais, sinais de pontuação ou outros elementos de texto. Grande parte do trabalho inicial na implementação desse tipo de funcionalidade foi realizada pelos serviços de correios para dar ajudar na classificação automática de correspondências com base em CEPs. Desde então, a tecnologia de última geração para a leitura de texto avançou e já temos modelos que detectam textos impressos ou manuscritos em uma imagem e leem-nos linha por linha e palavra por palavra.

Nenhum comentário:
Postar um comentário