HTTP oferece suporte a vários métodos para acessar um recurso. No protocolo HTTP, vários métodos de solicitação permitem que o navegador envie informações, formulários ou arquivos ao servidor. Esses métodos são usados, entre outras coisas, para informar ao servidor como processar a solicitação que enviamos e como responder.
Vimos diferentes métodos HTTP usados nas solicitações HTTP testadas nas seções anteriores. Com cURL, se usarmos -v para visualizar a solicitação completa, a primeira linha contém o método HTTP (por exemplo, GET / HTTP/1.1), enquanto com os devtools do navegador (F12), o método HTTP é mostrado na coluna Método. Além disso, os cabeçalhos de resposta também contêm o código de resposta HTTP, que indica o status do processamento de nossa solicitação HTTP.
Métodos de solicitação
A seguir estão alguns dos métodos comumente usados:
GET: Solicita um recurso específico. Dados adicionais podem ser passados ao servidor por meio de strings de consulta na URL (por exemplo, ?param=value).
POST: Envia dados para o servidor. Ele pode lidar com vários tipos de entrada, como texto, PDFs e outras formas de dados binários. Esses dados são anexados ao corpo da solicitação, presente após os cabeçalhos. O método POST é comumente usado ao enviar informações (por exemplo, formulários/logins) ou fazer upload de dados para um site, como imagens ou documentos.
HEAD: Solicita os cabeçalhos que seriam retornados se uma solicitação GET fosse feita ao servidor. Ele não retorna o corpo da solicitação e geralmente é feito para verificar o comprimento da resposta antes de baixar os recursos.
PUT: Cria novos recursos no servidor. Permitir esse método sem controles adequados pode levar ao upload de recursos maliciosos.
DELETE: Exclui um recurso existente no servidor web. Se não for devidamente protegido, pode levar à negação de serviço (DoS), excluindo arquivos críticos no servidor web.
OPTIONS: Retorna informações sobre o servidor, como os métodos por ele aceitos.
PATCH: Aplica modificações parciais ao recurso no local especificado.
A lista destaca apenas alguns dos métodos HTTP mais comumente usados. A disponibilidade de um método específico depende do servidor e também da configuração do aplicativo. Para obter uma lista completa de métodos HTTP, você pode visitar este link.
Nota: A maioria dos aplicativos web modernos depende principalmente dos métodos GET e POST. No entanto, qualquer aplicativo web que utiliza APIs REST também depende de PUT e DELETE, que são usados para atualizar e excluir dados no endpoint da API, respectivamente. Consulte o módulo Introdução às Aplicações Web para obter mais detalhes.
Códigos de resposta
Os códigos de status HTTP são usados para informar ao cliente o status de sua solicitação. Um servidor HTTP pode retornar cinco tipos de códigos de resposta:
1xx Fornece informações e não afeta o processamento da solicitação.
2xx Retornado quando uma solicitação é bem-sucedida.
3xx Retornado quando o servidor redireciona o cliente.
4xx Significa solicitações indevidas do cliente. Por exemplo, solicitar um recurso que não existe ou solicitar um formato incorreto.
5xx Retornado quando há algum problema com o próprio servidor HTTP.
A seguir estão alguns dos exemplos comumente vistos de cada um dos tipos de método HTTP acima:
200 OK Retornado em uma solicitação bem-sucedida e o corpo da resposta geralmente contém o recurso solicitado.
302 Found (Encontrado) Redireciona o cliente para outra URL. Por exemplo, redirecionando o usuário para seu painel após um login bem-sucedido.
400 Bad Request Retornado ao encontrar solicitações malformadas, como solicitações com terminadores de linha ausentes.
403 Forbidden (Proibido) Significa que o cliente não tem acesso apropriado ao recurso. Também pode ser retornado quando o servidor detecta uma entrada maliciosa do usuário.
404 Not Found (Não Encontrado) Retornado quando o cliente solicita um recurso que não existe no servidor.
500 Internal Server Error (Erro interno do servidor) Retornado quando o servidor não consegue processar a solicitação.
Para obter uma lista completa dos códigos de resposta HTTP padrão, você pode visitar este link. Além dos códigos HTTP padrão, vários servidores e provedores, como Cloudflare ou AWS, implementam seus próprios códigos.
GET (PEGAR)
Sempre que visitamos qualquer URL(Uniform Resource Locator), nossos navegadores usam como padrão uma solicitação GET para obter os recursos remotos hospedados naquela URL. Assim que o navegador recebe a página inicial que está solicitando; ele pode enviar outras solicitações usando vários métodos HTTP. Isso pode ser observado através da aba Rede no devtools do navegador, conforme visto na seção anterior.
Exercício: Escolha qualquer site de sua preferência e monitore a guia Rede nas ferramentas de desenvolvimento do navegador conforme você o visita para entender o desempenho da página. Essa técnica pode ser usada para entender completamente como uma aplicação web interage com seu back-end, o que pode ser um exercício essencial para qualquer avaliação de aplicação web ou exercício de recompensa de bugs.
Autenticação básica HTTP
Quando visitamos o exercício encontrado no final desta seção, ele nos solicita a inserção de um nome de usuário e uma senha. Ao contrário dos formulários de login usuais, que utilizam parâmetros HTTP para validar as credenciais do usuário (por exemplo, solicitação POST), este tipo de autenticação utiliza uma autenticação HTTP básica, que é tratada diretamente pelo servidor web para proteger uma página/diretório específico, sem interagir diretamente com o aplicativo da web.
Para acessar a página, temos que inserir um par válido de credenciais, que neste caso são admin:admin:
http://<SERVER_IP>:<PORT>/
Assim que inserirmos as credenciais, teremos acesso à página:
http://<SERVER_IP>:<PORT>/

Vamos tentar acessar a página com cURL e adicionaremos -i para visualizar os cabeçalhos de resposta:
venelouis@vene$ curl -i http://<SERVER_IP>:<PORT>/
HTTP/1.1 401 Authorization Required
Date: Mon, 21 Feb 2022 13:11:46 GMT
Server: Apache/2.4.41 (Ubuntu)
Cache-Control: no-cache, must-revalidate, max-age=0
WWW-Authenticate: Basic realm="Access denied"
Content-Length: 13
Content-Type: text/html; charset=UTF-8
Access deniedComo podemos ver, obtemos Acesso negado no corpo da resposta e também obtemos Basic realm="Access negado" no cabeçalho WWW-Authenticate, o que confirma que esta página realmente usa autenticação HTTP básica, conforme discutido na seção Headers (Cabeçalhos). Para fornecer as credenciais por meio de cURL, podemos usar o sinalizador -u, como segue:
venelouis@vene$ curl -u admin:admin http://<SERVER_IP>:<PORT>/
<!DOCTYPE html>
<html lang="en">
<head>
...SNIP...Desta vez, obtemos a página na resposta. Existe outro método pelo qual podemos fornecer as credenciais básicas de autenticação HTTP, que é diretamente por meio da URL como (nome de usuário: senha@URL), conforme discutimos na primeira seção. Se tentarmos o mesmo com cURL ou nosso navegador, também teremos acesso à página:
venelouis@vene$ curl http://admin:admin@<SERVER_IP>:<PORT>/
<!DOCTYPE html>
<html lang="en">
<head>
...SNIP...Também podemos tentar visitar o mesmo URL em um navegador e também devemos ser autenticados.
Exercício: Tente visualizar os cabeçalhos de resposta adicionando -i à solicitação acima e veja como uma resposta autenticada difere de uma não autenticada.
Cabeçalho de autorização HTTP
Se adicionarmos a flag -v a qualquer um dos nossos comandos cURL anteriores:
venelouis@venelouis$ curl -v http://admin:admin@<SERVER_IP>:<PORT>/
* Trying <SERVER_IP>:<PORT>...
* Connected to <SERVER_IP> (<SERVER_IP>) port PORT (#0)
* Server auth using Basic with user 'admin'
> GET / HTTP/1.1
> Host: <SERVER_IP>
> Authorization: Basic YWRtaW46YWRtaW4=
> User-Agent: curl/7.77.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Date: Mon, 21 Feb 2022 13:19:57 GMT
< Server: Apache/2.4.41 (Ubuntu)
< Cache-Control: no-store, no-cache, must-revalidate
< Expires: Thu, 19 Nov 1981 08:52:00 GMT
< Pragma: no-cache
< Vary: Accept-Encoding
< Content-Length: 1453
< Content-Type: text/html; charset=UTF-8
<
<!DOCTYPE html>
<html lang="en">
<head>
...SNIP...Como estamos usando autenticação HTTP básica, vemos que nossa solicitação HTTP define o cabeçalho de autorização como Basic YWRtaW46YWRtaW4=, que é o valor codificado em base64 de admin:admin. Se estivéssemos usando um método moderno de autenticação (por exemplo, JWT), a Autorização seria do tipo Bearer e conteria um token criptografado mais longo.
Vamos tentar definir manualmente a Autorização, sem fornecer as credenciais, para ver se ela nos permite acesso à página. Podemos definir o cabeçalho com a flag -H e usaremos o mesmo valor da solicitação HTTP acima. Podemos adicionar a flag -H várias vezes para especificar vários cabeçalhos:
venelouis@vene$ curl -H 'Authorization: Basic YWRtaW46YWRtaW4='
http://<SERVER_IP>:<PORT>/
<!DOCTYPE html
<html lang="en">
<head>
...SNIP...Como vemos, isso também nos deu acesso à página. Estes são alguns métodos que podemos usar para autenticar a página. A maioria dos aplicativos da web modernos usa formulários de login criados com linguagem de script de back-end (por exemplo, PHP), que utiliza solicitações HTTP POST para autenticar os usuários e, em seguida, retornar um cookie para manter sua autenticação.
Parâmetros GET
Uma vez autenticados, temos acesso a uma função City Search, na qual podemos inserir um termo de pesquisa e obter uma lista de cidades correspondentes:
À medida que a página retorna nossos resultados, ela pode entrar em contato com um recurso remoto para obter as informações e, em seguida, exibi-las na página. Para verificar isso, podemos abrir o devtools do navegador e ir até a aba Rede, ou usar o atalho [CTRL+SHIFT+E] para chegar à mesma aba. Antes de inserirmos nosso termo de pesquisa e visualizarmos as solicitações, talvez seja necessário clicar no ícone da lixeira no canto superior esquerdo, para garantir que limpamos todas as solicitações anteriores e monitoramos apenas as solicitações mais recentes:
Depois disso, podemos inserir qualquer termo de pesquisa e pressionar Enter, e notaremos imediatamente uma nova solicitação sendo enviada ao backend:
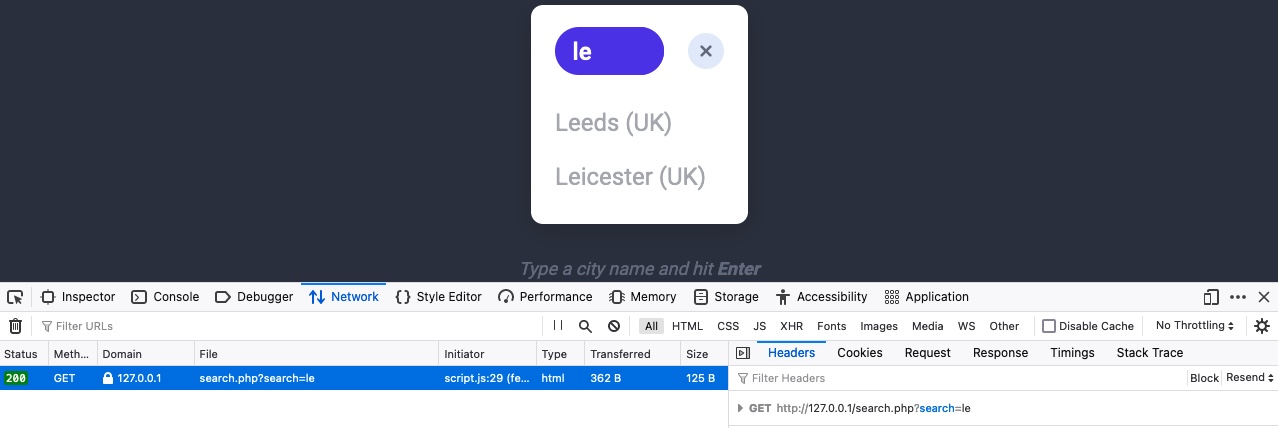
Quando clicamos na solicitação, ela é enviada para search.php com o parâmetro GET search=le usado na URL. Isso nos ajuda a entender que a função de pesquisa solicita outra página para os resultados.
Agora, podemos enviar a mesma solicitação diretamente para search.php para obter os resultados completos da pesquisa, embora provavelmente os retorne em um formato específico (por exemplo, JSON) sem ter o layout HTML mostrado na imagem acima.
Para enviar uma solicitação GET com cURL, podemos usar exatamente o mesmo URL visto nas capturas de tela acima, pois as solicitações GET colocam seus parâmetros no URL. No entanto, os devtools do navegador fornecem um método mais conveniente de obter o comando cURL. Podemos clicar com o botão direito na solicitação e selecionar Copiar>Copiar como cURL. Então, podemos colar o comando copiado em nosso terminal e executá-lo, e devemos obter exatamente a mesma resposta:
venelouis@vene$ curl 'http://<SERVER_IP>:<PORT>/search.php?search=le' -H
'Authorization: Basic YWRtaW46YWRtaW4='
Leeds (UK)
Leicester (UK)Nota: O comando copiado conterá todos os cabeçalhos usados na solicitação HTTP. No entanto, podemos remover a maioria deles e manter apenas os cabeçalhos de autenticação necessários, como o cabeçalho Authorization.
Também podemos repetir a solicitação exata diretamente nas ferramentas de desenvolvimento do navegador, selecionando Copiar>Copiar como busca. Isso copiará a mesma solicitação HTTP usando a biblioteca JavaScript Fetch. Então, podemos ir para a aba do console JavaScript clicando em [CTRL+SHIFT+K], colar nosso comando Fetch e pressionar enter para enviar a solicitação:
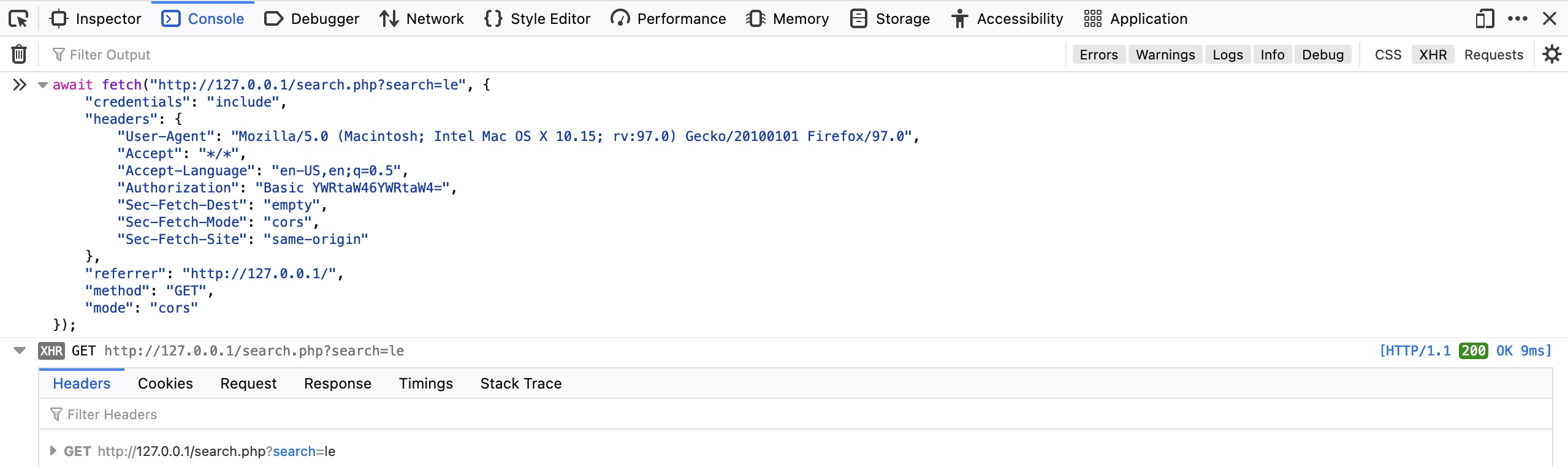
https://www.youtube.com/watch?v=ytn5kTFSj8I

Nenhum comentário:
Postar um comentário