Protocolo de transferência de hipertexto seguro
(HTTPS: Hypertext Transfer Protocol Secure)
Em uma seção anterior, discutimos como as solicitações HTTP são enviadas e processadas. No entanto, uma das desvantagens significativas do HTTP é que todos os dados são transferidos em texto não criptografado. Isso significa que qualquer pessoa entre a origem e o destino pode realizar um ataque Man-in-the-middle (MiTM) para visualizar os dados transferidos.
Para combater esse problema, foi criado o protocolo HTTPS (HTTP Secure), no qual todas as comunicações são transferidas em formato criptografado, de forma que, mesmo que terceiros interceptem a solicitação, não conseguirão extrair os dados dela. Por esse motivo, o HTTPS se tornou o esquema principal para sites na Internet, e o HTTP está sendo eliminado e em breve a maioria dos navegadores não permitirá a visita a sites HTTP.
Visão geral do HTTPS
Se examinarmos uma solicitação HTTP, podemos ver o efeito de não impor comunicações seguras entre um navegador web e uma aplicação web. Por exemplo, a seguir está o conteúdo de uma solicitação de login HTTP:
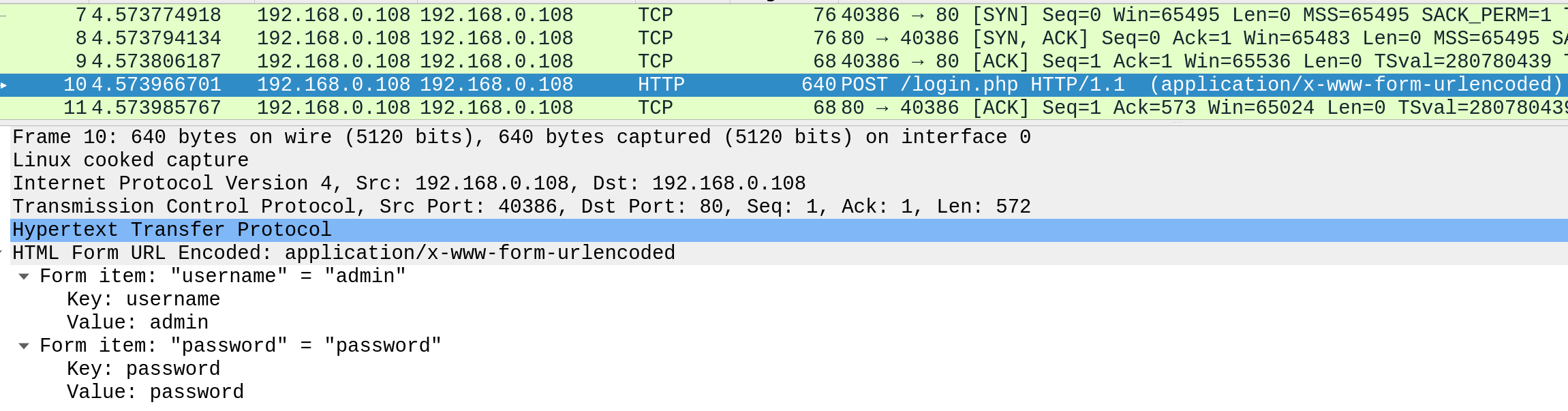
Podemos ver que as credenciais de login podem ser visualizadas em texto não criptografado. Isso tornaria mais fácil para alguém na mesma rede (como uma rede sem fio pública) capturar a solicitação e reutilizar as credenciais para fins maliciosos.
Por outro lado, quando alguém intercepta e analisa o tráfego de uma solicitação HTTPS, verá algo como o seguinte:
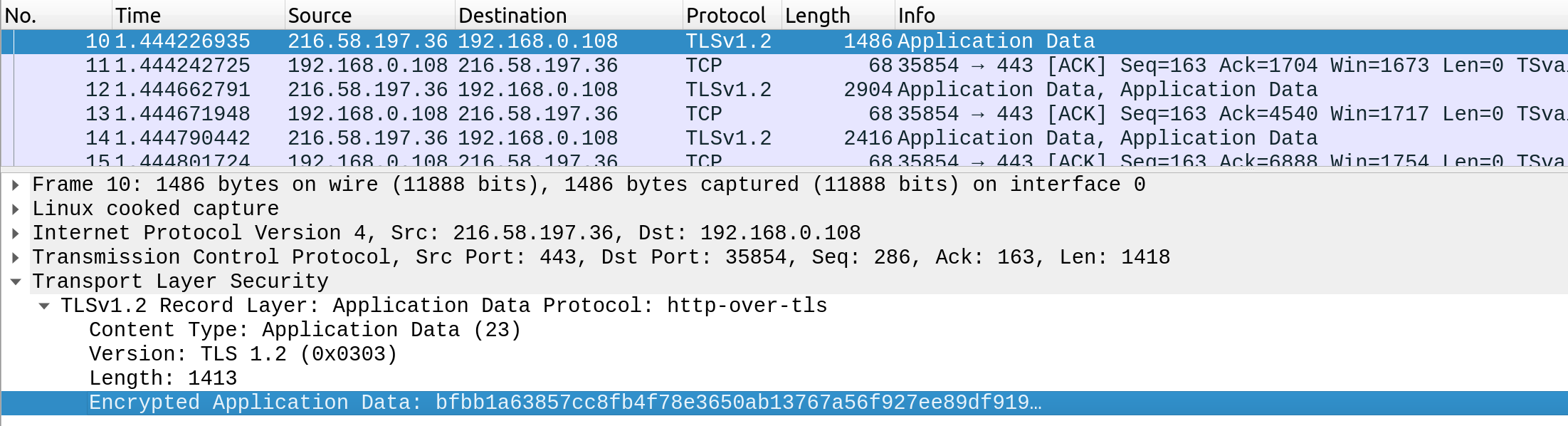
Como podemos ver, os dados são transferidos como um único fluxo criptografado, o que torna muito difícil para qualquer pessoa capturar informações como credenciais ou quaisquer outros dados confidenciais.
Os sites que aplicam HTTPS podem ser identificados por https:// em seu URL (por exemplo, https://www.google.com), bem como pelo ícone de cadeado na barra de endereço do navegador, à esquerda do URL:
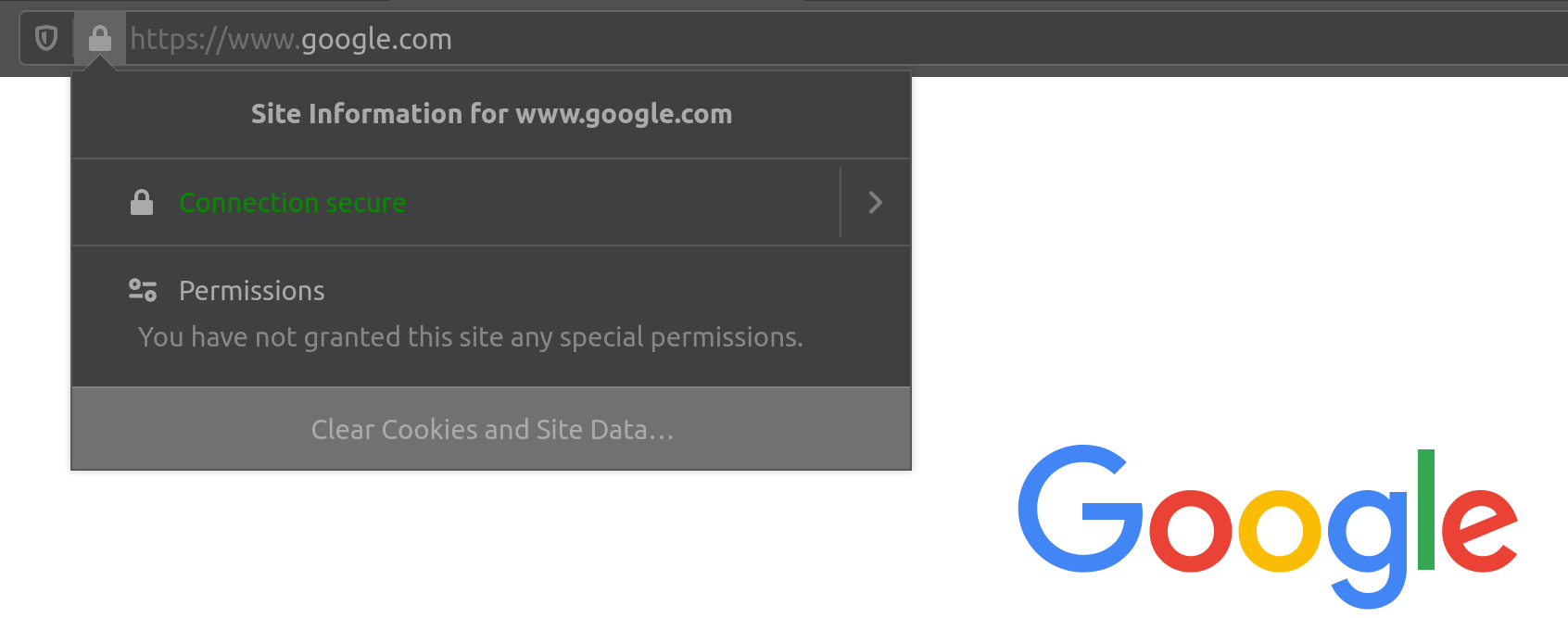
Portanto, se visitarmos um site que utiliza HTTPS, como o Google, todo o tráfego será criptografado.
Observação: embora os dados transferidos por meio do protocolo HTTPS possam ser criptografados, a solicitação ainda poderá revelar o URL visitado se entrar em contato com um servidor DNS de texto não criptografado. Por esse motivo, é recomendável utilizar servidores DNS criptografados (por exemplo, 8.8.8.8 ou 1.1.1.1) ou utilizar um serviço VPN para garantir que todo o tráfego seja devidamente criptografado.
Fluxo HTTPS
Vejamos como o HTTPS opera em alto nível:
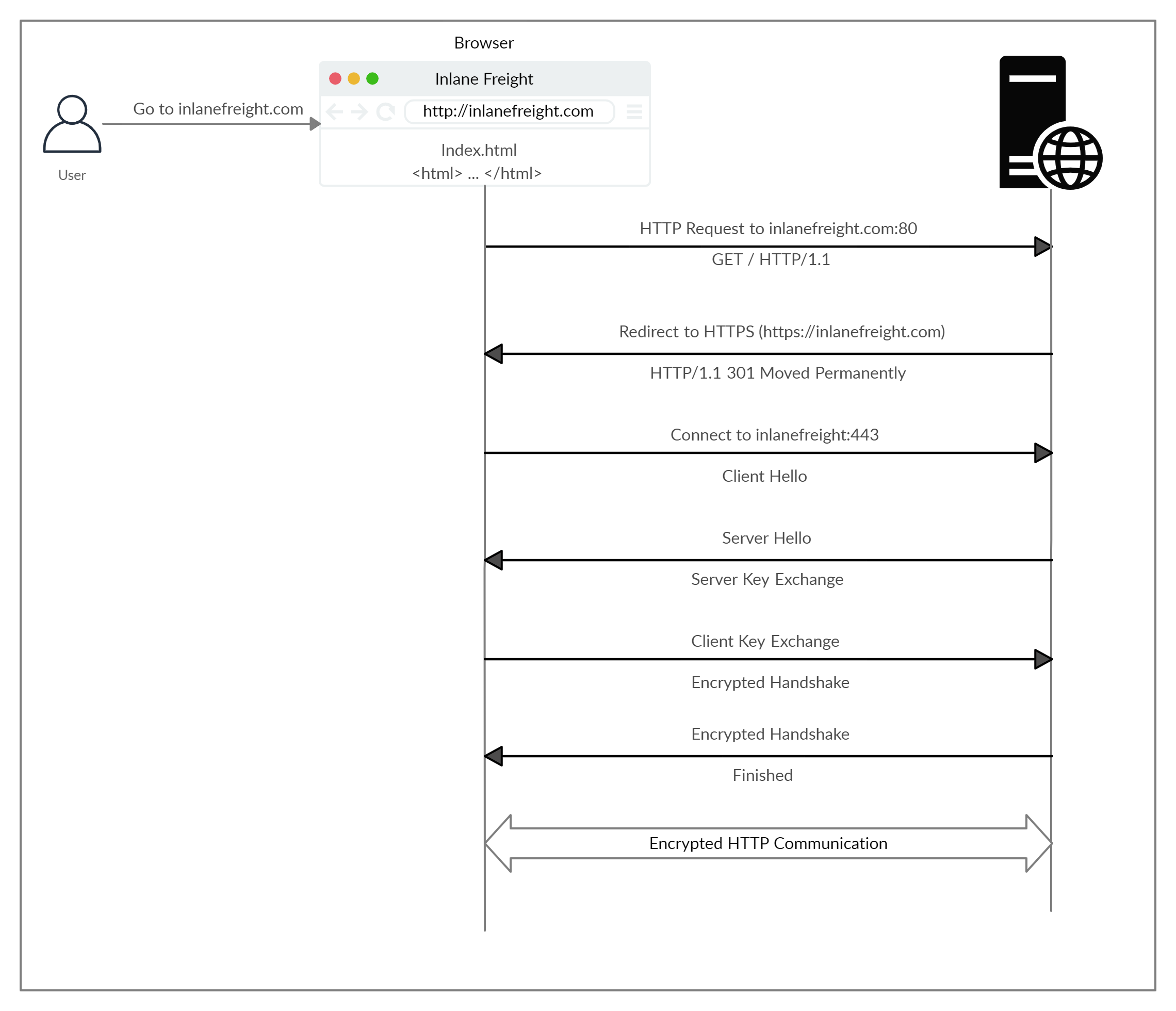
Se digitarmos http:// em vez de https:// para visitar um site que aplica HTTPS, o navegador tentará resolver o domínio e redirecionará o usuário para o servidor web que hospeda o site de destino. Uma solicitação é enviada primeiro para a porta 80, que é o protocolo HTTP não criptografado. O servidor detecta isso e redireciona o cliente para a porta HTTPS 443 segura. Isso é feito por meio do código de resposta 301 Moved Permanently, que discutiremos em uma próxima seção.
Em seguida, o cliente (navegador web) envia um pacote “client hello”, fornecendo informações sobre si mesmo. Depois disso, o servidor responde com “server hello”, seguido de uma troca de chaves para troca de certificados SSL. O cliente verifica a chave/certificado e envia um próprio. Depois disso, um handshake criptografado é iniciado para confirmar se a criptografia e a transferência estão funcionando corretamente.
Depois que o handshake for concluído com êxito, a comunicação HTTP normal continuará, que será criptografada depois disso. Esta é uma visão geral de alto nível da troca de chaves, que está além do escopo deste módulo.
Nota: Dependendo das circunstâncias, um invasor pode executar um ataque de downgrade HTTP, que rebaixa a comunicação HTTPS para HTTP, fazendo com que os dados sejam transferidos em texto não criptografado. Isso é feito configurando um proxy Man-In-The-Middle (MITM) para transferir todo o tráfego através do host do invasor sem o conhecimento do usuário. No entanto, a maioria dos navegadores, servidores e aplicações web modernos protegem contra esse ataque.
cURL para HTTPS
cURL deve lidar automaticamente com todos os padrões de comunicação HTTPS e executar um handshake seguro e, em seguida, criptografar e descriptografar os dados automaticamente. No entanto, se alguma vez entrarmos em contato com um site com um certificado SSL inválido ou desatualizado, o cURL, por padrão, não prosseguirá com a comunicação para proteção contra os ataques MITM mencionados anteriormente:
Terminal:
venelouis@venelouis$ curl https://inlanefreight.com
curl: (60) SSL certificate problem: Invalid certificate chain
More details here: https://curl.haxx.se/docs/sslcerts.html
...SNIP...
Os navegadores modernos fariam o mesmo, alertando o usuário contra a visita a um site com um certificado SSL inválido.
Podemos enfrentar esse problema ao testar um aplicativo Web local ou com um aplicativo Web hospedado para fins práticos, pois esses aplicativos Web podem ainda não ter implementado um certificado SSL válido. Para pular a verificação do certificado com cURL, podemos usar o sinalizador -k:
Terminal:
venelouis@venelouis$ curl -k https://inlanefreight.com
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
...SNIP...
Como podemos perceber, a solicitação foi processada neste momento e recebemos os dados da resposta.
Solicitações e respostas HTTP (requests and responses)
As comunicações HTTP consistem principalmente em uma solicitação HTTP e uma resposta HTTP. Uma solicitação HTTP é feita pelo cliente (por exemplo, cURL/navegador) e processada pelo servidor (por exemplo, servidor web). As solicitações contêm todos os detalhes que solicitamos do servidor, incluindo o recurso (por exemplo, URL, caminho, parâmetros), quaisquer dados da solicitação, cabeçalhos ou opções que especificamos e muitas outras opções que discutiremos ao longo deste módulo.
Depois que o servidor recebe a solicitação HTTP, ele a processa e responde enviando a resposta HTTP, que contém o código de resposta, conforme discutido em uma seção posterior, e pode conter os dados do recurso se o solicitante tiver acesso a ele.
Solicitação HTTP (request)
Vamos começar examinando o seguinte exemplo de solicitação HTTP:
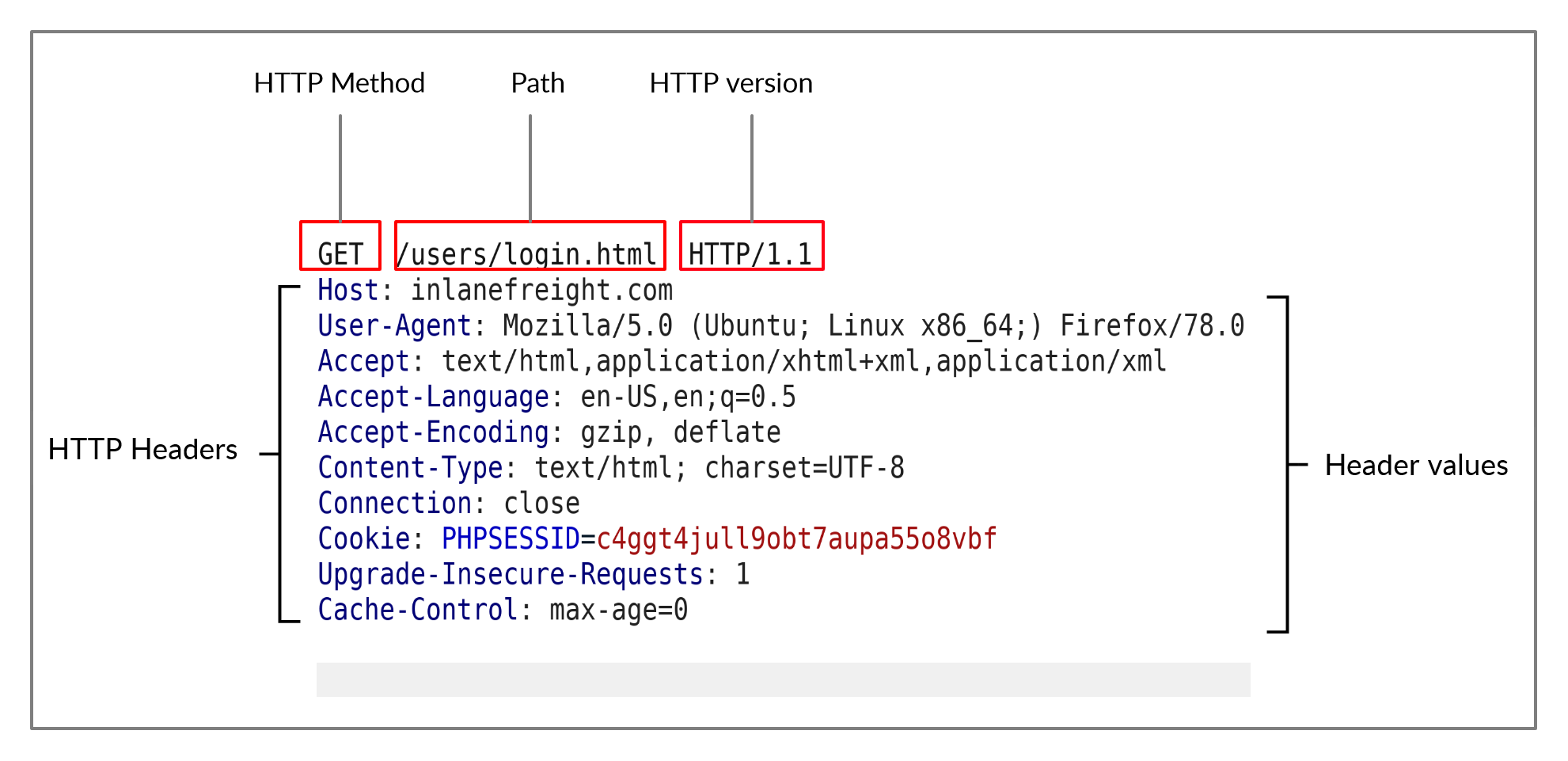
A imagem acima mostra uma solicitação HTTP GET para o URL:
- http://inlanefreight.com/users/login.html
A primeira linha de qualquer solicitação HTTP contém três campos principais ‘separados por espaços’:
- Campo/ Área: Método
- Exemplo: GET (pegar, receber, obter)
- Descrição: O método ou verbo HTTP, que especifica o tipo de ação a ser executada.
- Campo/ Área: Path (caminho)
- Exemplo: /users/login.html
- Descrição: O caminho para o recurso que está sendo acessado. Este campo também pode ser sufixado com uma string de consulta (por exemplo, ?username=user).
- Campo / Área: Versão
- Exemplo: HTTP/1.1
- Descrição: O terceiro e último campo é usado para indicar a versão HTTP.
O próximo conjunto de linhas contém pares de valores de cabeçalho HTTP, como Host, User-Agent, Cookie e muitos outros cabeçalhos possíveis. Esses cabeçalhos são usados para especificar vários atributos de uma solicitação. Os cabeçalhos terminam com uma nova linha, necessária para que o servidor valide a solicitação. Finalmente, uma solicitação pode terminar com o corpo e os dados da solicitação.
Nota: O HTTP versão 1.X envia solicitações como texto não criptografado e usa um caractere de nova linha para separar campos e solicitações diferentes. O HTTP versão 2.X, por outro lado, envia solicitações como dados binários em formato de dicionário.
Resposta HTTP (response)
Depois que o servidor processa nossa solicitação, ele envia sua resposta. A seguir está um exemplo de resposta HTTP:
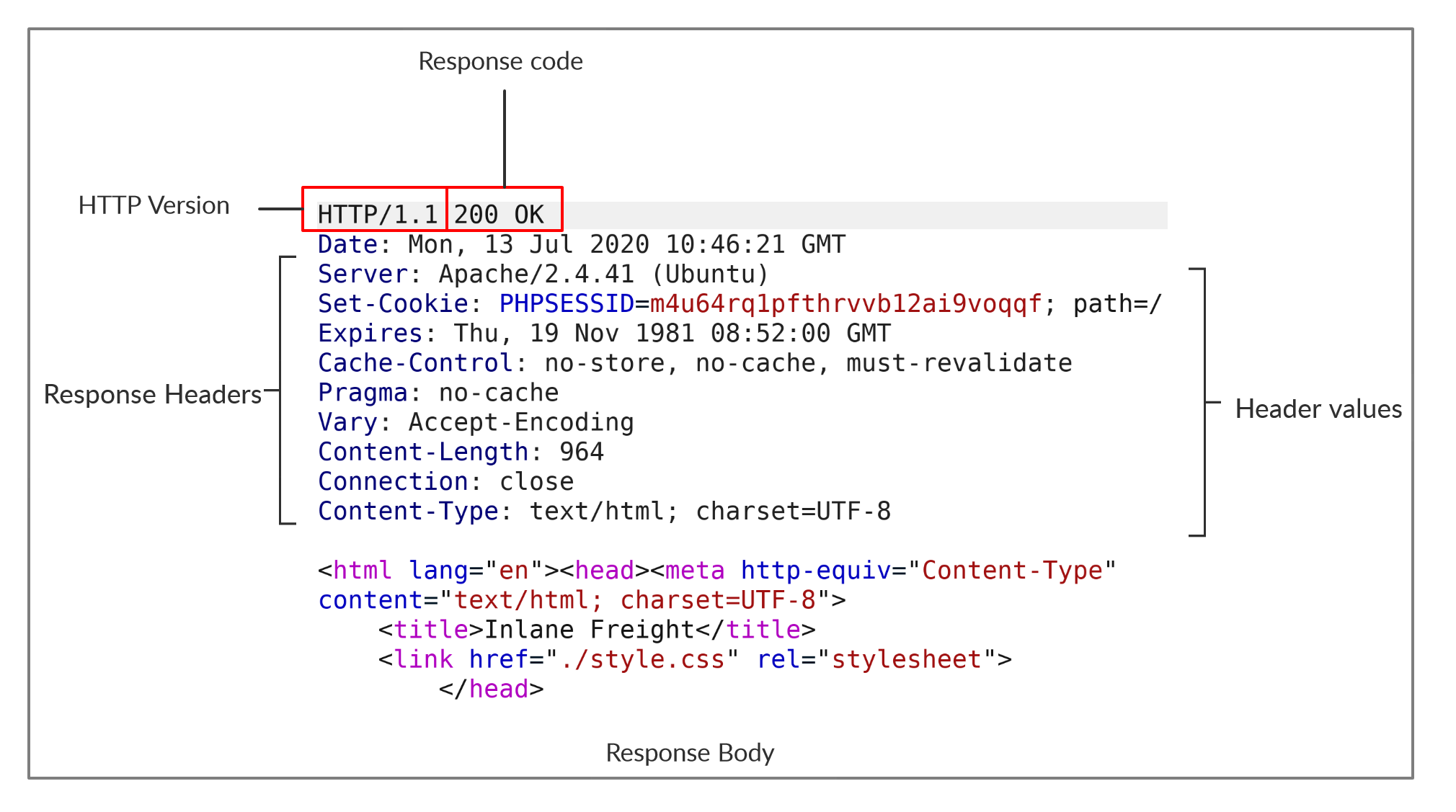
A primeira linha de uma resposta HTTP contém dois campos separados por espaços. A primeira é a versão HTTP (por exemplo, HTTP/1.1) e a segunda denota o código de resposta HTTP (por exemplo, 200 OK).
Os códigos de resposta são usados para determinar o status da solicitação, conforme será discutido em uma seção posterior. Após a primeira linha, a resposta lista seus cabeçalhos, semelhante a uma solicitação HTTP. Os cabeçalhos de solicitação e resposta serão discutidos na próxima seção.
Finalmente, a resposta pode terminar com um corpo de resposta, que é separado por uma nova linha após os cabeçalhos. O corpo da resposta geralmente é definido como código HTML. No entanto, ele também pode responder com outros tipos de código, como JSON, recursos de sites como imagens, folhas de estilo ou scripts, ou até mesmo um documento como um documento PDF hospedado no servidor web.
cURL
Em nossos exemplos anteriores com cURL, especificamos apenas a URL e obtivemos o corpo da resposta em troca. No entanto, cURL também nos permite visualizar a solicitação HTTP completa e a resposta HTTP completa, o que pode ser muito útil ao realizar testes de penetração na web ou escrever explorações. Para visualizar a solicitação e a resposta HTTP completas, podemos simplesmente adicionar o sinalizador -v detalhado aos nossos comandos anteriores, e ele deve imprimir a solicitação e a resposta:
Terminal:
venelouis@venelouis$ curl inlanefreight.com -v
* Trying SERVER_IP:80...
* TCP_NODELAY set
* Connected to inlanefreight.com (SERVER_IP) port 80 (#0)
> GET / HTTP/1.1
> Host: inlanefreight.com
> User-Agent: curl/7.65.3
> Accept: */*
> Connection: close
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 401 Unauthorized
< Date: Tue, 21 Jul 2020 05:20:15 GMT
< Server: Apache/X.Y.ZZ (Ubuntu)
< WWW-Authenticate: Basic realm="Restricted Content"
< Content-Length: 464
< Content-Type: text/html; charset=iso-8859-1
<
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
...SNIP...
Como podemos ver, desta vez obtemos a solicitação e a resposta HTTP completas. A solicitação simplesmente enviou GET/HTTP/1.1 junto com os cabeçalhos Host, User-Agent e Accept. Em troca, a resposta HTTP continha HTTP/1.1 401 Unauthorized, o que indica que não temos acesso ao recurso solicitado, como veremos em uma próxima seção. Semelhante à solicitação, a resposta também continha vários cabeçalhos enviados pelo servidor, incluindo Data, Comprimento do Conteúdo e Tipo de Conteúdo. Finalmente, a resposta continha o corpo da resposta em HTML, que é o mesmo que recebemos anteriormente ao usar cURL sem o sinalizador -v.
Exercício: O sinalizador -vvv mostra uma saída ainda mais detalhada. Tente usar esse sinalizador para ver quais detalhes extras de solicitação e resposta são exibidos com ele.
Ferramentas de desenvolvimento do navegador
A maioria dos navegadores modernos vem com ferramentas de desenvolvedor integradas (DevTools), que se destinam principalmente aos desenvolvedores testarem seus aplicativos da web. No entanto, como testadores de penetração na web, essas ferramentas podem ser um ativo vital em qualquer avaliação da web que realizamos, já que um navegador (e suas DevTools) estão entre os ativos que provavelmente teremos em todos os exercícios de avaliação da web. Neste módulo, também discutiremos como utilizar algumas das ferramentas básicas de desenvolvimento do navegador para avaliar e monitorar diferentes tipos de solicitações da web.
Sempre que visitamos qualquer site ou acessamos qualquer aplicativo da web, nosso navegador envia diversas solicitações da web e processa diversas respostas HTTP para renderizar a visualização final que vemos na janela do navegador. Para abrir os devtools do navegador no Chrome ou Firefox, podemos clicar em [CTRL+SHIFT+I] ou simplesmente clicar em [F12]. Os devtools contêm várias guias, cada uma com seu próprio uso. Estaremos nos concentrando principalmente na guia Rede neste módulo, pois ela é responsável pelas solicitações da web.
Se clicarmos na aba Rede e atualizarmos a página, poderemos ver a lista de solicitações enviadas pela página:
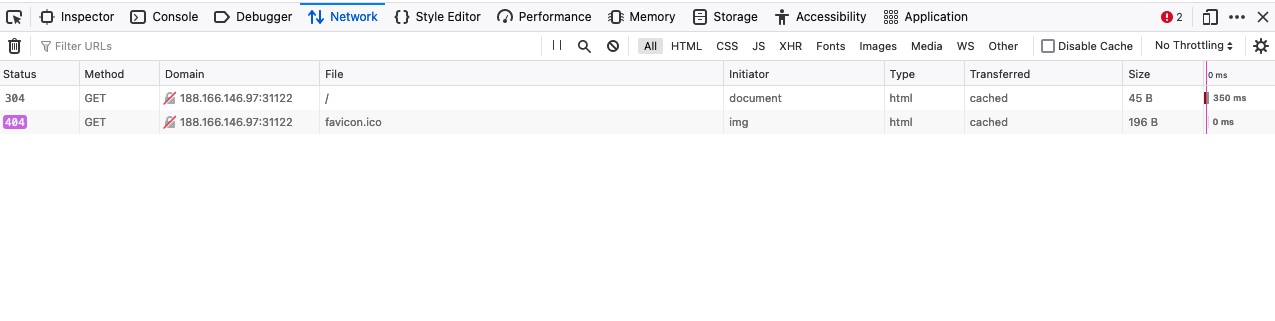
Como podemos ver, os devtools nos mostram rapidamente o status da resposta (ou seja, código de resposta), o método de solicitação usado (GET), o recurso solicitado (ou seja, URL/domínio), junto com o caminho solicitado. Além disso, podemos usar Filtrar URLs para pesquisar uma solicitação específica, caso o site carregue muitas para ser processado.

Nenhum comentário:
Postar um comentário