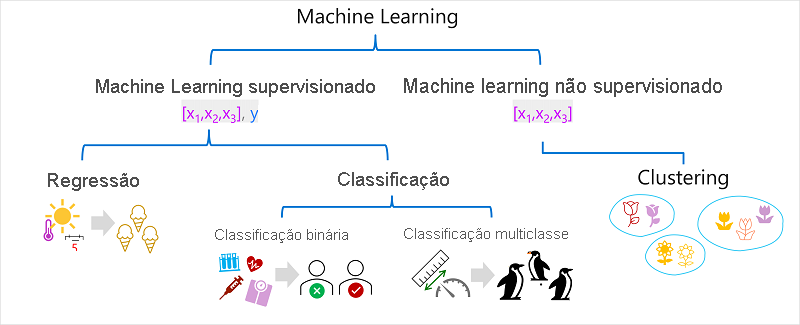
1. Machine Learning supervisionado
O aprendizado de máquina Supervisionado é um termo geral para algoritmos de aprendizado de máquina em que os dados de treinamento incluem valores de recursos e valores conhecidos de rótulo. O aprendizado de máquina supervisionado é utilizado para treinar modelos determinando um relacionamento entre os recursos e os rótulos em observações passadas, de modo que rótulos desconhecidos possam ser previstos para recursos em casos futuros.
1.1. Regressão
Regressão é uma forma de aprendizado de máquina supervisionado em que o rótulo previsto pelo modelo é um valor numérico. Por exemplo:
- O número de sorvetes vendidos em um determinado dia, com base na temperatura, na chuva e na velocidade do vento.
- O preço de venda de um imóvel com base no seu tamanho em pés quadrados, no número de quartos que contém e nas métricas socioeconômicas da sua localização.
- A eficiência de combustível (em milhas por galão) de um carro com base no tamanho do motor, peso, largura, altura e comprimento.
1.2. Classificação
Classificação é uma forma de aprendizado de máquina supervisionado em que o rótulo representa uma categorização, ou classe. Existem dois cenários comuns de classificação.
1.2.1. Classificação binária
Na classificação binária, o rótulo determina se o item observado é (ou não é) uma instância de uma classe específica. Em outras palavras, os modelos de classificação binária preveem um de dois resultados mutuamente exclusivos. Por exemplo:
- Se um paciente está em risco de diabetes com base em métricas clínicas como peso, idade, nível de glicose no sangue e assim por diante.
- Se um cliente do banco ficará inadimplente em um empréstimo com base na renda, no histórico de crédito, na idade e em outros fatores.
- Se um cliente da lista de emails responderá positivamente a uma oferta de marketing com base nos atributos demográficos e nas compras anteriores.
- Em todos esses exemplos, o modelo prevê uma previsão binária verdadeira/falsa ou positiva/negativa para uma única classe possível.
1.2.2. Classificação multiclasse
A classificação multiclasse amplia a classificação binária para prever um rótulo que representa uma das várias classes possíveis. Por exemplo,
- A espécie de um pinguim (Adélia, Gentoo ou Chinstrap) com base em suas medidas físicas.
- O gênero de um filme (comédia, terror, romance, aventura ou ficção científica) com base na equipe de elenco, no diretor e no orçamento.
Na maioria dos cenários que envolvem um conjunto conhecido de várias classes, a classificação multiclasse é utilizada para prever rótulos mutuamente exclusivos. Por exemplo, um pinguim não pode ser um Gentoo e um Adélia. Entretanto, há também alguns algoritmos que você pode utilizar para treinar os modelos de classificação com vários rótulos, nos quais pode existir mais de um rótulo válido para uma única observação. Por exemplo, um filme poderia ser potencialmente categorizado como ficção científica e comédia.
2. Aprendizado de máquina não supervisionado
O aprendizado de máquina não supervisionado envolve o treinamento de modelos usando dados que consistem apenas em valores de recursos sem rótulos conhecidos. Os algoritmos de aprendizado de máquina não supervisionados determinam relacionamentos entre os recursos das observações nos dados de treinamento.
2.1. Clustering
A forma mais comum de aprendizado de máquina não supervisionado é o clustering. Um algoritmo de clustering identifica semelhanças entre observações com base nos seus recursos e as agrupa em clusters discretos. Por exemplo:
- Agrupe flores semelhantes com base no tamanho, no número de folhas e no número de pétalas.
- Identificar os grupos de clientes semelhantes com base nos atributos demográficos e no comportamento de compra.
Em alguns aspectos, o clustering é semelhante à classificação multiclasse, pois categoriza as observações em grupos discretos. A diferença é que, ao usar a classificação, você já conhece as classes às quais pertencem as observações nos dados de treinamento; portanto, o algoritmo funciona determinando o relacionamento entre os recursos e o rótulo de classificação conhecido. No clustering, não existe um rótulo de cluster previamente conhecido e o algoritmo agrupa as observações de dados com base puramente na similaridade dos recursos.
Em alguns casos, o clustering é utilizado para determinar o conjunto de classes existentes antes de treinar um modelo de classificação. Por exemplo, você deve usar o clustering para segmentar seus clientes em grupos e, em seguida, analisar esses grupos para identificar e categorizar diferentes classes de clientes (alto valor - baixo volume, pequenos compradores frequentes e assim por diante). Em seguida, você pode usar suas categorizações para rotular as observações nos resultados do clustering e usar os dados rotulados para treinar um modelo de classificação que preveja a qual categoria de cliente um novo cliente pode pertencer.
Aprendizado
O aprendizado profundo é uma forma avançada de aprendizado de máquina que tenta emular a maneira como o cérebro humano aprende. A chave para o aprendizado profundo é a criação de uma rede neural artificial que simula a atividade eletroquímica em neurônios biológicos utilizando funções matemáticas, como mostrado aqui.

As redes neurais artificiais são compostas de várias camadas de neurônios - essencialmente definindo uma função profundamente aninhada. Essa arquitetura é o motivo pelo qual a técnica é chamada de aprendizado profundo e os modelos produzidos por ela são frequentemente chamados de redes neurais profundas (DNNs). Você pode utilizar redes neurais profundas para muitos tipos de problemas de aprendizado de máquina, incluindo regressão e classificação, bem como modelos mais especializados para processamento de linguagem natural e pesquisa visual computacional.
Assim como outras técnicas de aprendizado de máquina discutidas neste módulo, o aprendizado profundo envolve o ajuste dos dados de treinamento a uma função que pode prever um rótulo (y) com base no valor de um ou mais recursos (x). A função (f(x)) é a camada externa de uma função aninhada na qual cada camada da rede neural encapsula funções que operam em x e os valores de peso (w) associados a elas. O algoritmo utilizado para treinar o modelo envolve a alimentação iterativa dos valores dos recursos (x) nos dados de treinamento por meio das camadas para calcular as saídas para ŷ, validando o modelo para avaliar a distância entre os valores calculados ŷ e os valores conhecidos y (que quantifica o nível de erro, ou perda, no modelo) e, em seguida, modificando os pesos (w) para reduzir a perda. O modelo treinado inclui os valores finais de peso que resultam nas previsões mais precisas.
Como uma rede neural aprende?
Os pesos em uma rede neural são fundamentais para a forma como ela calcula os valores previstos para os rótulos. Durante o processo de treinamento, o modelo aprende os pesos que resultarão nas previsões mais precisas. Vamos explorar o processo de treinamento com um pouco mais de detalhes para entender como se dá esse aprendizado.
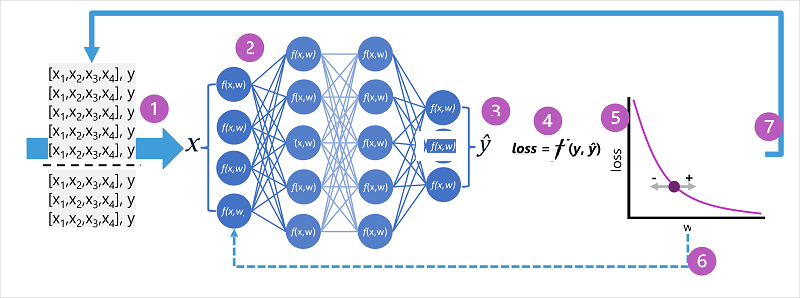
- Os conjuntos de dados de treinamento e validação são definidos e os recursos de treinamento alimentados na camada de entrada.
- Os neurônios em cada camada da rede aplicam seus pesos (que são inicialmente atribuídos de forma aleatória) e alimentam os dados por meio da rede.
- A camada de saída produz um vetor que contém os valores calculados para ŷ. Por exemplo, uma saída para uma previsão de classe de pinguim pode ser [0,3. 0,1. 0,6].
- Uma função de perda é utilizada para comparar os valores previstos ŷ com os valores conhecidos y e agregar a diferença (que é conhecida como perda). Por exemplo, se a classe conhecida para o caso que retornou a saída na etapa anterior for Chinstrap, então o valor y deverá ser [0.0, 0.0, 1.0]. A diferença absoluta entre isso e o vetor ŷ é [0,3, 0,1, 0,4]. Na realidade, a função de perda calcula a variação agregada de vários casos e a resume em um único valor de perda.
- Como a rede inteira é essencialmente uma grande função aninhada, uma função de otimização pode utilizar o cálculo diferencial para avaliar a influência de cada peso na rede sobre a perda e determinar como eles podem ser ajustados (para cima ou para baixo) para reduzir a quantidade de perda de modo geral. A técnica de otimização específica pode variar, mas geralmente envolve uma abordagem de descida de gradiente em que cada peso é aumentado ou diminuído para minimizar a perda.
- As alterações nos pesos são retropropagadas para as camadas da rede, substituindo os valores utilizados anteriormente.
- O processo é repetido em várias iterações (conhecidas como épocas) até que a perda seja minimizada e o modelo preveja com precisão aceitável.
Observação
Embora seja mais fácil pensar em cada caso dos dados de treinamento sendo passado pela rede um de cada vez, na realidade os dados são colocados em lote em matrizes e processados utilizando cálculos algébricos lineares. Por esse motivo, o treinamento da rede neural é melhor executado nos computadores com unidades de processamento gráfico (GPUs) otimizadas para a manipulação de vetores e matrizes.
Serviços de IA do Azure:
https://contentsafety.cognitive.azure.com
https://microsoftlearning.github.io/mslearn-ai-fundamentals/Instructions/Labs/02-content-safety.html

Algumas questões:
Quais são os três tipos de aprendizado de máquina?
- Aprendizado com supervisão
- Aprendizado sem supervisão
- Aprendizado com reforço
Os três usam algoritmos para aprender sobre dados, e conforme os algoritmos são expostos a mais dados, eles continuam aprendendo e melhorando os resultados.
O que é inteligência artificial?
- Técnicas que ajudam máquinas e computadores a imitarem o comportamento humano
Qual é o exemplo de emulação do cérebro inteiro, em que uma máquina pode pensar e tomar decisões sobre vários assuntos?
- IA Geral
Hoje, essa ramificação da IA é um objetivo, e não uma tecnologia prática. Ela exigirá décadas de pesquisas adicionais e a aquisição de computadores mais poderosos.
Quais são as instruções matemáticas que dizem à máquina como proceder para encontrar a solução de um problema?
- Algoritmos
É a base para a IA e diz ao computador exatamente quais são as etapas para se concluir uma tarefa ou resolver um problema.
Qual é o modelo de aprendizado de máquina que simula a interconectividade com o cérebro humano?
- Rede Neural
Esse tipo de modelo pode aprender coisas, reconhecer padrões e tomar decisões, sem precisar ser programado explicitamente.
Qual aplicação da IA dá aos computadores a capacidade de entender a linguagem humana conforme ela é falada?
- Processamento de linguagem natural
Uma máquina pode responder aos humanos com nuance e entendimento. Um exemplo comum é um chatbot de atendimento ao cliente.
Qual é o principal critério para que um computador ou IA passe no teste de Turing?
- Substituir um dos jogadores sem alterar substancialmente os resultados
Um computador pode ser considerado inteligente se sua conversa não for facilmente distinguida da fala de um humano.
Qual destes é a base de todos os sistemas de IA e permite que algoritmos revelem padrões e tendências?
- Dados
São o combustível da IA e podem ser estruturados ou não estruturados.
Qual ramificação da IA foca em modelos estatísticos para resolver problemas com redes neurais artificiais inspiradas no cérebro humano?
- Deep Learning
É uma tecnologia fundamental por trás dos carros que dirigem sozinhos, permitindo que o computador reconheça um sinal de pare ou diferencie um pedestre de um poste de iluminação.
Qual tecnologia permitirá que as empresas expandam a IA, operem novos algoritmos de treinamento e compartilhem dados através da Internet?
- Nuvem
Essa tecnologia de “internet” fornece aos algoritmos de IA acesso a grandes quantidades de dados.

Nenhum comentário:
Postar um comentário